このトピックは Windows 向け FRE に適用されます。
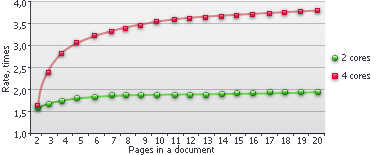
この図には、シナリオごとに異なり、並列化できないドキュメントのエクスポート処理は含まれていません。速度向上率も、ドキュメントの複雑さによって異なる場合があります。複雑なレイアウトのドキュメントでは高く、単純なドキュメントでは低くなります。解析と認識にかかる時間が長いほど、マルチプロセッシングの効果は大きくなります。また、この図は、ドキュメント内のページ数が多いほど、負荷分散とパフォーマンス効率が向上することも示しています。
Windows 上の ABBYY FineReader Engine におけるマルチ CPU 認識アーキテクチャ: 自動的なページ分散により、複数のコアに認識処理を分散し、より高いスループットを実現します。