Linux および Windows での PDF 入力
高度な PDF 処理 | ABBYY FineReader Engine は、入力 PDF ファイル内の次のような内部情報を解析します。
SDK は、効率的かつ正確にテキストを選択することで、PDF 変換のパフォーマンスと処理速度を向上させます。PDF ファイルにテキストが埋め込まれている場合、OCR エンジンはテキストレイヤーの整合性を確認し、テキストを抽出するか、ブロック単位で OCR を適用するかを判断します。 |
PDF 内部情報の取得 | 内部 PDF リンク、ハイパーリンクのほか、件名、作成者、title、キーワードなどのドキュメントプロパティを抽出します。 |
PDF出力
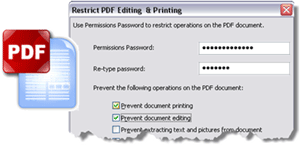
PDFのセキュリティおよび暗号化のサポート | ABBYY FineReader Engine 12 は、さまざまなPDF セキュリティ設定をサポートしており、高度なセキュリティが求められる政府機関やその他の組織での活用範囲を広げます。
|
Tagged PDF形式での出力 | Tagged PDF は、さまざまなページ幅や画面幅に合わせて「リフロー」できます。携帯端末 (PDA) や、視覚障害のあるユーザーが一般的に使用するスクリーンリーダーでの利用に適しています。 |
ページサイズ | PDF 変換時に、出力ファイルのすべてのページのサイズを設定できます。 |
メタデータのエクスポート | ABBYY FineReader Engine 12 では、メタデータ (ブックマーク、ハイパーリンク、相互参照など) をエクスポートできます。 |
PDF/A形式への変換 | ページ指向文書の長期保存の標準として推奨される PDF/A 形式に変換できます。 ABBYY の技術により、PDF/A-1a、PDF/A-1b、PDF/A-2a、PDF/A-2b、PDF/A-2u、PDF/A-3a、PDF/A-3b、PDF/A-3u など、準拠レベルの異なる PDF/A 形式でドキュメントを保存できます。 PDF/A-1a 形式には、次の特徴があります。ドキュメントの書式、論理構造、通常の外観を最も適切に保持できるほか、サイズの異なる表示装置でもドキュメントの外観を維持できます (これを実現するため、ドキュメントの内容は特定の方法で構成されます) 。 PDF/A-1b 形式は、ドキュメントの外観のみを再現するために使用されます。 PDF/A-2a、PDF/A-2b、PDF/A-2u 形式は、JPEG 2000 画像圧縮、透過、およびレイヤーをサポートします。違いは、PDF/A-2u ではすべてのテキストに Unicode マッピングがあることです。 PDF/A-3a、PDF/A-3b、PDF/A-3u 形式は、任意の形式のドキュメント (Excel、Word、HTML、CAD、XML など) を PDF ドキュメントに添付できます。 |
PDF/UA形式への変換 | ABBYY FineReader Engine 12 は、PDF/UA 標準に準拠した PDF へのエクスポートをサポートしています。PDF/UA 形式は、Tagged PDF と支援技術に対応しています。 |
CJK から PDF へのエクスポート | 中国語 (簡体字と繁体字の両方) 、日本語、韓国語のドキュメントを PDF 形式に変換できます。 |
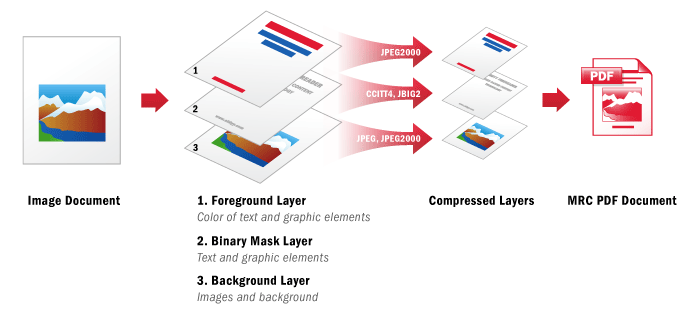
PDF (PDF/A) MRC圧縮
シンプルでわかりやすいPDF変換
| PDF書き出しシナリオ | 説明 |
|---|---|
| MaxQuality | 生成されるファイルの品質が最高になるように、PDF (PDF/A) 書き出しを最適化します。 |
| Balanced | PDF (PDF/A) 書き出しでは、生成されるファイルの品質、サイズ、処理時間のバランスを取ります。 |
| MinSize | 生成されるファイルのサイズが最小になるように、PDF (PDF/A) 書き出しを最適化します。 |
| MaxSpeed | 処理速度が最大になるように、PDF (PDF/A) 書き出しを最適化します。 |