-
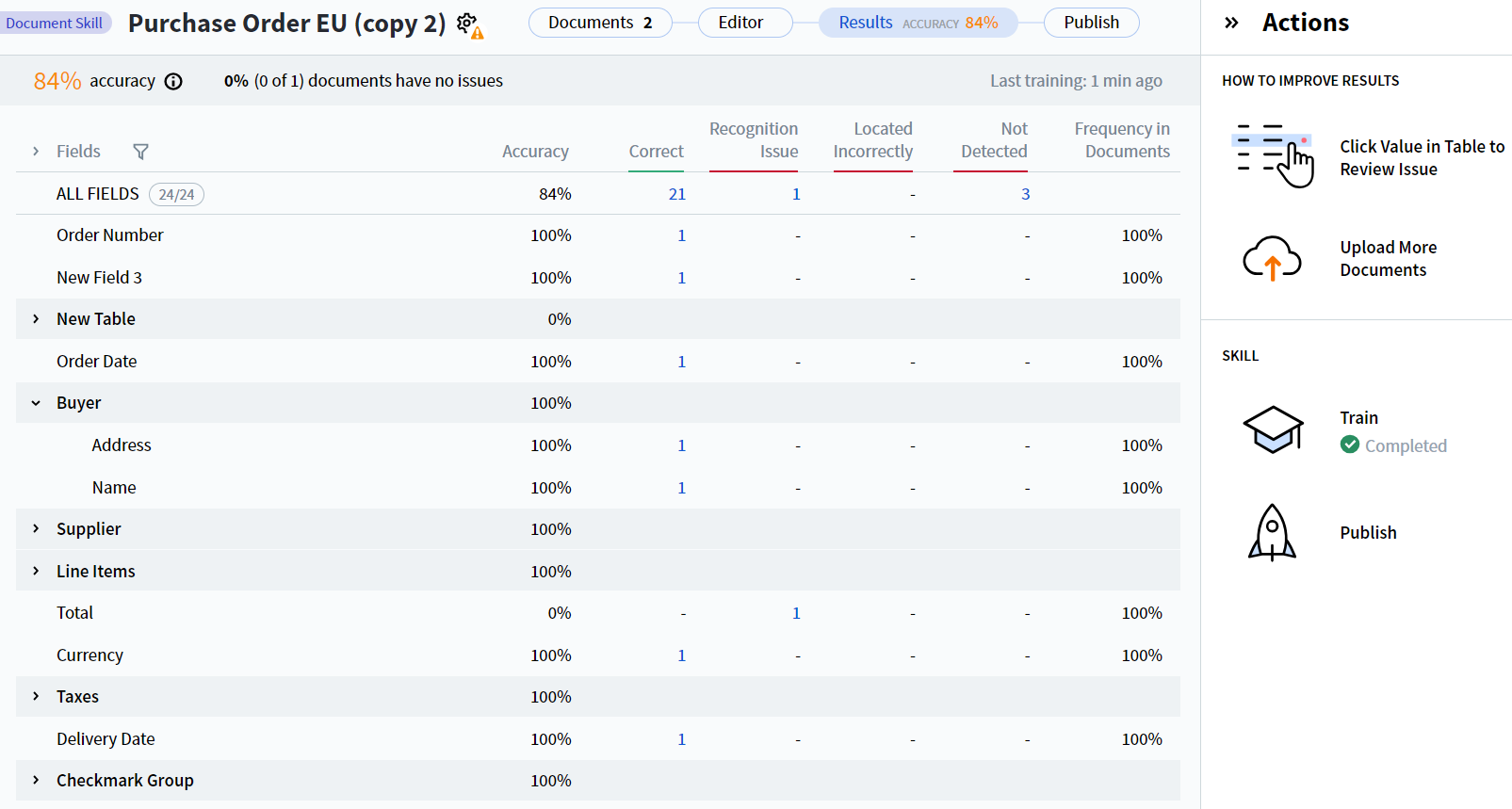
Accuracy — Percentage of fields with correctly extracted values, both per-field and across all fields (the ALL FIELDS row).
Per-field accuracy is calculated as:
The ALL FIELDS row uses the same formula, with each term aggregated across all fields.
- Correct — Number of field instances whose extracted value matched the reference value.
- Recognition Issue — Number of field instances detected in the document but not recognized correctly.
- Located Incorrectly — Number of field instances whose values differ from the predicted values because their regions were detected in locations different from those in the labeling.
- Not Detected — Number of undetected field instances.
- Frequency in Documents — Percentage of documents containing the given field.
For these statistics to reflect production quality, your test set’s document distribution should match what you see in production — for example, if 30% of your production invoices come from a particular vendor, about 30% of the test set should too. Using a blind set (documents not used for training or prior testing) further validates the results.
Review fields extracted with errors
To view documents that contain fields extracted with errors, click the value in the Recognition Issue, Located Incorrectly, or Not Detected column for the field you’re investigating.Clicking the value in the Recognition Issue column for the Order Date field opens a tab showing only documents where Order Date had a recognition issue.
View extraction modes
The Result Review tab lets you review the extraction results, labeling errors, and recognition issues — and compare the setup-time labeling with what training produced. Documents can be viewed in three modes:- Reference — Shows the reference labeling created when setting up the skill (before training) and the field values extracted using it. Field values and regions can be edited in this mode.
- Predicted — Shows the field values and regions obtained when processing documents. Not editable.
- Difference — Shows the differences between reference and predicted labeling. Identical values and regions appear in green; differing ones appear in red. Not editable.
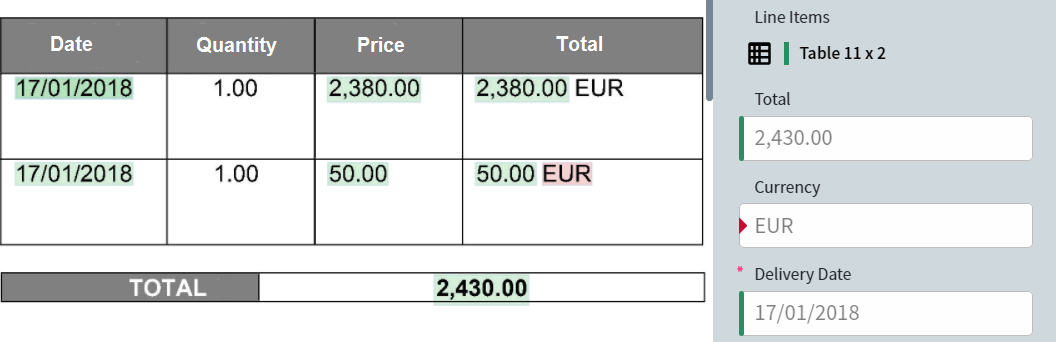
Correct reference labeling
If a field was labeled incorrectly during setup but processed correctly during training, you can update the reference labeling. Switch to Difference mode and click the icon above the value of the mislabeled field: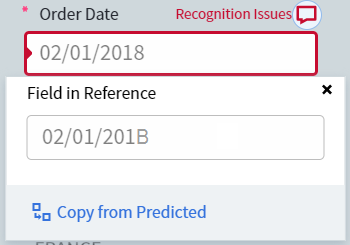
Related topics
Adding fields
Mark fields in the Editor tab and configure field properties by type.
Rule verification
Use rules to validate, modify, or compute extracted field values in a Document skill.
Labeling documents
Guidelines for labeling structured and semi-structured documents during training.
Training and testing a Document skill
Advanced Designer guide for training, testing, and measuring Document skill quality.