Bevor Sie beginnen
Öffnen Sie die Aktivität im Activity Editor
- Öffnen Sie die Aktivität “Sick Note DE” im Activity Editor.
- Wählen Sie eines der Dokumente aus dem Dokumentensatz aus.
Aktivieren Sie erweiterte Elementeigenschaften
Extrahieren Sie die Patientendaten
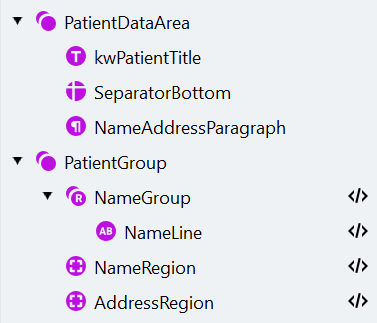
Erstellen Sie die Gruppe PatientDataArea
- Klicken Sie auf Create Element und wählen Sie das Element Group aus der Dropdown-Liste aus. Ändern Sie seinen Namen in “PatientDataArea”.
- Ändern Sie im Abschnitt Under what conditions den Wert Element is in Optional.
Suchen Sie das Patientenlabel mit einem Static Text-Element
- Klicken Sie auf Create Element und wählen Sie das Element Static Text aus der Dropdown-Liste aus. Ändern Sie den Namen in “kwPatientTitle”.
- Geben Sie den Text “Name, Vorname” in das Feld Text to find im Bereich Properties ein.
- Klicken Sie auf Match. Wenn die Verarbeitung abgeschlossen ist, sehen Sie unter dem Dokument den Hypothesenbaum.
- Vergewissern Sie sich, dass Advanced Designer den statischen Text erfolgreich gefunden hat — ein grüner Punkt neben dem Elementnamen weist auf eine erfolgreiche Übereinstimmung hin.
- Klicken Sie im Hypothesenbaum auf den Elementnamen, damit ein violetter Rahmen um die entsprechende Region im Dokument angezeigt wird.
Ermitteln Sie die untere Grenze mit einem Separator
- Fügen Sie der Gruppe ein Separator-Element hinzu und nennen Sie es “SeparatorBottom”. Setzen Sie die Mindestlänge auf 200.
- Klicken Sie mit der rechten Maustaste auf das Element und wählen Sie im Kontextmenü Match Element aus. Der Tree of Hypotheses enthält viele grüne Punkte — sie entsprechen verschiedenen Trennlinien, die den Suchkriterien entsprechen. Klicken Sie auf jeden Punkt, um das zugehörige Objekt auf dem Bild anzuzeigen.
- Um die Suchkriterien einzugrenzen, legen Sie den Suchbereich für die Trennlinie fest:
- Klicken Sie auf Match, um das Element “kwPatientTitle” zu finden, das als Ankerelement verwendet wird.
- Klicken Sie im Abschnitt Where to search im Bereich Properties auf Draw on Image.
- Wählen Sie im Dokument das Element “kwPatientTitle” aus. Klicken Sie auf das Symbol mit dem Abwärtspfeil, um den Suchbereich unterhalb des Schlüsselworts festzulegen, und auf das Symbol für den nächstgelegenen Separator, um nach der dem Schlüsselwort nächstgelegenen Trennlinie zu suchen.
- Klicken Sie auf Match und prüfen Sie, ob Advanced Designer die Trennlinie unterhalb des Elements “kwPatientTitle” gefunden hat.
Absatz mit Name und Adresse finden
- Erstellen Sie ein Paragraph-Suchelement und nennen Sie es “NameAddressParagraph”.
- Ändern Sie Text alignment in Left.
- Die Daten des Patienten umfassen zwei bis fünf Zeilen. Geben Sie daher für Line count 2 bis 5 an.
- Geben Sie den Suchbereich für den Absatz über das Menü Add im Abschnitt Where to search an. Das Element sollte sich unter dem Element “kwPatientTitle” und über dem Element “SeparatorBottom” befinden.
- Klicken Sie auf Match.
PatientGroup erstellen
Die wiederholbare Gruppe NameGroup konfigurieren
- Erstellen Sie ein Suchelement vom Typ Wiederholbare Gruppe und nennen Sie es “NameGroup”. Geben Sie 2 als maximale Anzahl von Wiederholungen an. Legen Sie das Element als optional fest.
-
Um den Suchbereich auf die Zeilen zu beschränken, die zum Absatz “NameAddressParagraph” gehören, klicken Sie auf das Symbol des Code-Editors unter dem Dokumentbild und fügen Sie das folgende Skript im Abschnitt Suchbedingungen des Code Editor ein:
- Erstellen Sie innerhalb der wiederholbaren Gruppe ein Element vom Typ Zeichenfolge, das eine Zeichenzeile erfassen soll. Nennen Sie es “NameLine”.
-
Der gesuchte Text kann Groß- und Kleinbuchstaben sowie verschiedene Satzzeichen enthalten. Konfigurieren Sie zwei separate Zeichensätze:
- Der erste Satz enthält alle lateinischen Groß- und Kleinbuchstaben. Um Zeichen mit diakritischen Zeichen hinzuzufügen, ändern Sie den Unicode-Unterbereich oder fügen Sie die Zeichen direkt in das Feld Ausgewählte Zeichen ein.
- Der zweite Satz enthält die Satzzeichen: ,-.()’. Damit die Zeichenfolge nicht nur aus Satzzeichen besteht, setzen Sie Anteil im Text, % für den zweiten Satz auf 40 %.
- Deaktivieren Sie die Option Nach Wortteilen suchen.
- Geben Sie den Suchbereich für das Element “NameLine” an: unterhalb des Elements “kwPatientTitle” und möglichst nah daran.
- Klicken Sie auf Abgleichen und prüfen Sie den Hypothesenbaum. Es werden zwei Zeichenfolgen gefunden, aber die zweite enthält die Adresse des Patienten.
-
Um die Adresse aus den Suchergebnissen auszuschließen, fügen Sie eine skriptbasierte Suchbedingung hinzu:
- Wählen Sie das Suchelement “NameLine” aus und öffnen Sie den Code-Editor für Suchbedingungen.
-
Fügen Sie das folgende Skript ein — es geht davon aus, dass die erste Zeile einen vollständigen Namen enthält, wenn sie ein Komma und ein Leerzeichen enthält. Wenn ein vollständiger Name gefunden wird, beendet die wiederholbare Gruppe die Suche nach einer zweiten Instanz:
- Klicken Sie auf Abgleichen und stellen Sie sicher, dass der Name korrekt gefunden wird.
Erstellen Sie das Element „NameRegion“ vom Typ Region
- Erstellen Sie in der Gruppe “PatientGroup” ein Region-Suchelement und benennen Sie es in “NameRegion” um.
-
Öffnen Sie den Code Editor und fügen Sie das folgende Skript im Abschnitt Search Conditions ein:
Erstellen Sie das Region-Element AddressRegion
Patientenfelder erstellen und zuordnen
Art der Krankschreibung extrahieren
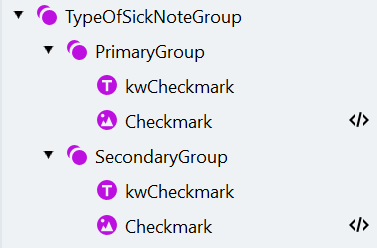
Die TypeOfSickNoteGroup und PrimaryGroup erstellen
Die PrimaryGroup konfigurieren
- Erstellen Sie innerhalb der Gruppe “PrimaryGroup” ein Element vom Typ Static Text mit dem Namen “kwCheckmark” (zu suchender Text: “Erstbescheinigung”).
- Dieses Element steht nicht mit den zuvor gesuchten Elementen in Zusammenhang. Führen Sie statt eines Matchings des gesamten Elementbaums ein Matching nur für das neue Element durch, indem Sie im Kontextmenü des Elements “kwCheckmark” auf Match Element klicken. Stellen Sie sicher, dass das Schlüsselwort erfolgreich gefunden wurde.
- Suchen Sie nun das Häkchen mithilfe eines Elements vom Typ Object Collection, das verwendet wird, um verschiedene grafische Objekte wie Häkchen, Barcodes und Bilder zu finden.
- Fügen Sie ein Object Collection-Element mit dem Namen “Checkmark” hinzu.
- Deaktivieren Sie in der Dropdown-Liste Type im Bereich Properties alle Optionen außer Checkmark.
- Legen Sie die Mindestbreite und -höhe des Objekts auf 30 sowie die maximale Breite und Höhe auf 130 fest.
- Geben Sie den Suchbereich für das Häkchen links vom Element “kwCheckmark” an.
-
Das Häkchen sollte sich ungefähr in derselben Zeile wie das Schlüsselwort befinden. Geben Sie an, wo die obere und untere Begrenzung des Elements in Bezug auf das Schlüsselwort liegen sollen, indem Sie den folgenden Code in den Abschnitt Search Conditions des Code Editor einfügen:
- Klicken Sie auf Match.
Die SecondaryGroup erstellen und konfigurieren
- Kopieren Sie die Gruppe “PrimaryGroup” und benennen Sie die Kopie in “SecondaryGroup” um.
- Beim Kopieren einer Gruppe kopieren Sie auch alle ihre Elemente mit ihren Eigenschaften. Wählen Sie das Element “kwCheckmark” in der Gruppe “SecondaryGroup” aus und ändern Sie den zu suchenden Text in “Folgebescheinigung”.
- Das Object Collection-Suchelement findet eine Sammlung aller passenden Objekte innerhalb des Suchbereichs. Wenn sich die Häkchen in derselben Zeile befinden, kann das Element “Checkmark” der “SecondaryGroup” auch das primäre Häkchen finden. Um dies zu vermeiden, schließen Sie das primäre Häkchen (das Element “Checkmark” der “PrimaryGroup”) aus dem Suchbereich für das Element “Checkmark” aus der “SecondaryGroup” aus.
- Klicken Sie auf Match.
Die Felder für die Art der Krankschreibung erstellen und zuordnen
Extrahieren der Arztdaten
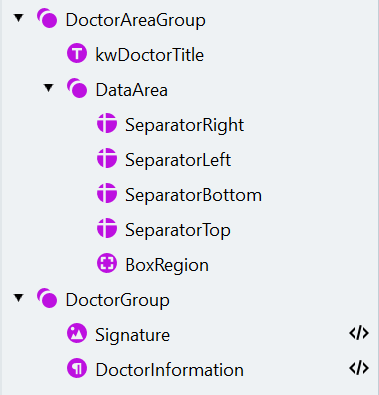
Erstellen Sie DoctorAreaGroup und DataArea
- Erstellen Sie ein Group-Element mit dem Namen “DoctorAreaGroup” und machen Sie das Element optional.
- Um die Beschriftung des Kastens zu finden, erstellen Sie ein Static Text-Element namens “kwDoctorTitle” (zu suchender Text: “Unterschrift des Arztes”).
- Erstellen Sie innerhalb der Gruppe “DoctorAreaGroup” eine weitere Gruppe mit dem Namen “DataArea”.
Fügen Sie die vier begrenzenden Trennlinien hinzu
BoxRegion erstellen
Erstellen Sie die Gruppe DoctorGroup
Hinzufügen der Object Collection „Signature“
Fügen Sie den Absatz „DoctorInformation“ hinzu
Prüfen Sie, ob die Elemente gefunden werden
Erstellen und Zuordnen der Arztfelder