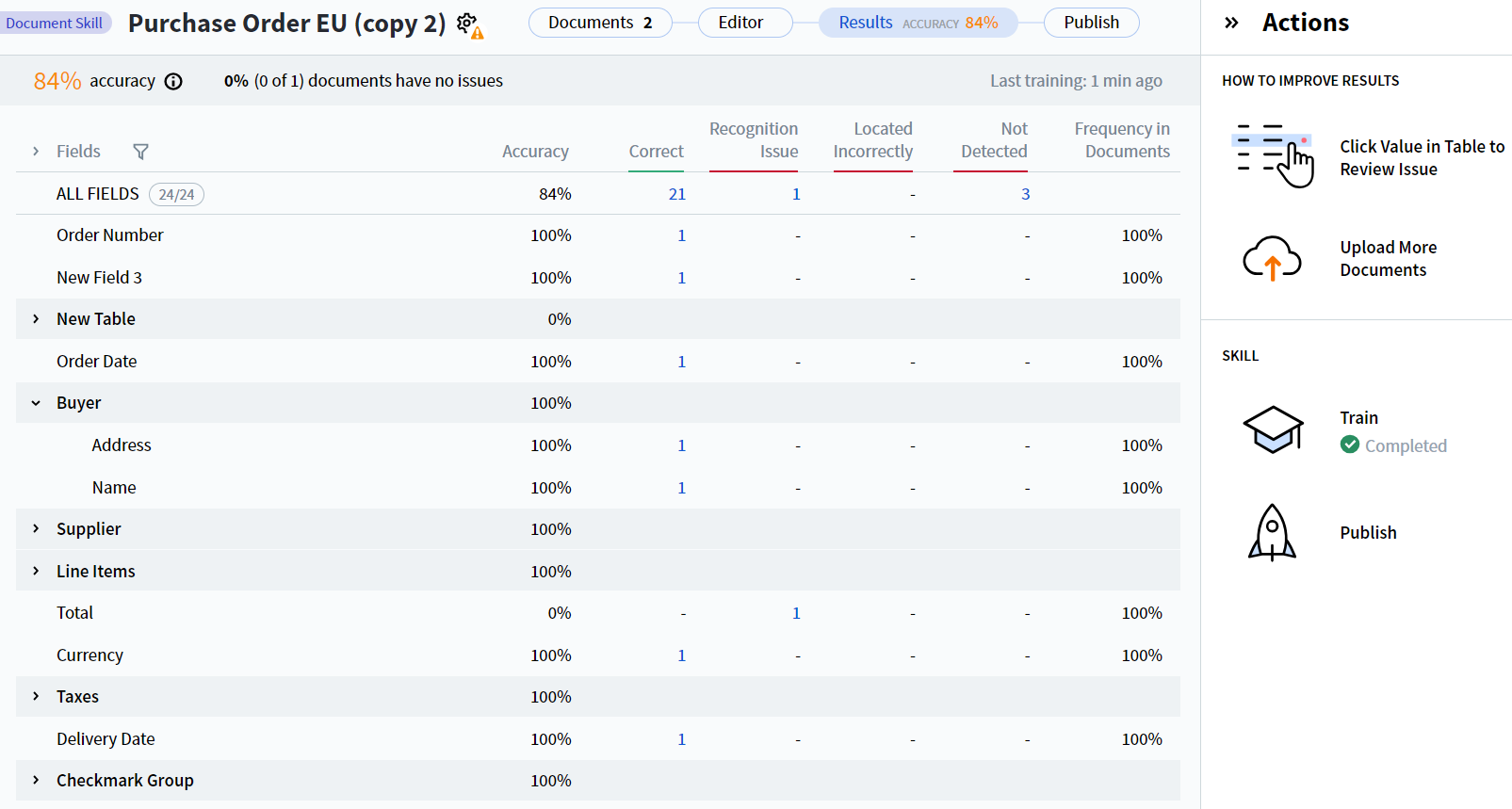
Die Registerkarte Results im Document Skill Designer enthält Statistiken zur Feldextraktion für Document-Skills. Anhand dieser Statistiken können Sie erkennen, wie sich die Extraktionsqualität verbessern lässt.
Alle vom Skill extrahierten Felder werden in der Spalte Fields angezeigt. Felder, die zu einer Gruppe gehören, werden in einer eingeklappten Dropdown-Liste zusammengefasst, die nach der jeweiligen Gruppe benannt ist.
Die folgenden Statistiken zur Feldextraktion sind verfügbar:
-
Accuracy — Prozentsatz der Felder mit korrekt extrahierten Werten, sowohl pro Feld als auch über alle Felder hinweg (die Zeile ALL FIELDS).
Die Genauigkeit pro Feld wird wie folgt berechnet:
Die Zeile ALL FIELDS verwendet dieselbe Formel, wobei jeder Term über alle Felder aggregiert wird.
-
Correct — Anzahl der Feldinstanzen, deren extrahierter Wert mit dem Referenzwert übereinstimmt.
-
Recognition Issue — Anzahl der Feldinstanzen, die im Dokument erkannt, aber nicht korrekt erkannt wurden.
-
Located Incorrectly — Anzahl der Feldinstanzen, deren Werte von den vorhergesagten Werten abweichen, weil ihre Regionen an anderen Positionen erkannt wurden als in der Kennzeichnung.
-
Not Detected — Anzahl der nicht erkannten Feldinstanzen.
-
Frequency in Documents — Prozentsatz der Dokumente, die das angegebene Feld enthalten.
Standardmäßig werden Statistiken für alle Felder angezeigt. Um zu filtern, klicken Sie oben in der Spalte Fields auf das Filtersymbol und wählen die Felder aus, die angezeigt werden sollen.
Für eine eingehendere Qualitätsanalyse — Precision, Recall und F-measure sowohl für Feldwerte als auch für die Regionserkennung — bearbeiten Sie Ihren Skill in Advanced Designer. Details finden Sie unter Advanced Accuracy Reports. Damit diese Statistiken die Produktionsqualität widerspiegeln, sollte die Verteilung der Dokumente in Ihrem Testsatz der Verteilung in der Produktion entsprechen — wenn beispielsweise 30 % Ihrer Produktionsrechnungen von einem bestimmten Vendor stammen, sollten dies auch etwa 30 % des Testsatzes sein. Die Verwendung eines blind set (Dokumente, die nicht für das Training oder frühere Tests verwendet wurden) bestätigt die Ergebnisse zusätzlich.
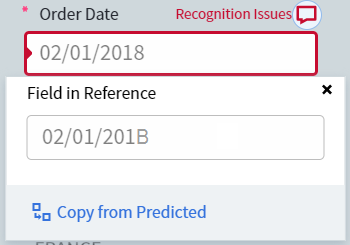
Wenn Sie auf den Wert in der Spalte Recognition Issue für das Feld Order Date klicken, wird eine Registerkarte geöffnet, auf der nur die Dokumente angezeigt werden, bei denen für Order Date ein Erkennungsproblem aufgetreten ist.
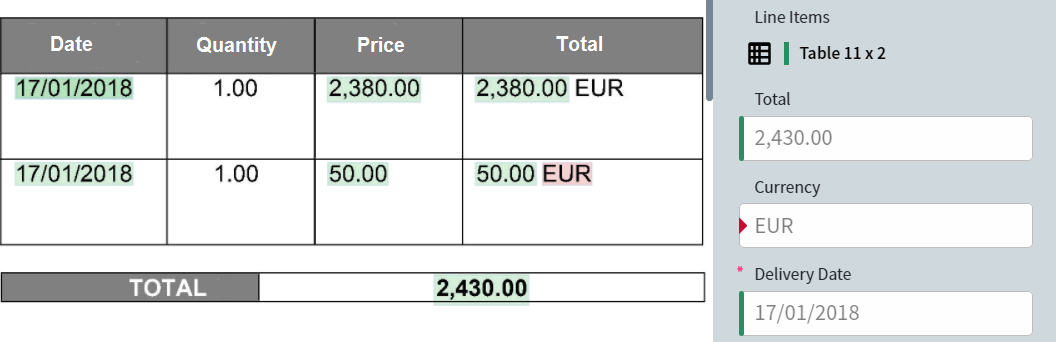
- Reference — Zeigt die Referenzkennzeichnung, die beim Einrichten des Skills erstellt wurde (vor dem Training), sowie die damit extrahierten Feldwerte. Feldwerte und Regionen können in diesem Modus bearbeitet werden.
- Predicted — Zeigt die Feldwerte und Regionen, die bei der Verarbeitung von Dokumenten ermittelt wurden. Nicht bearbeitbar.
- Difference — Zeigt die Unterschiede zwischen der Referenzkennzeichnung und der vorhergesagten Kennzeichnung. Identische Werte und Regionen werden grün angezeigt, abweichende rot. Nicht bearbeitbar.
Wechseln Sie zwischen den Modi, indem Sie auf die entsprechende Registerkarte in der Symbolleiste klicken.
Korrekte Referenzkennzeichnung
Ein Erkennungsproblem bedeutet, dass ein oder mehrere Zeichen nicht korrekt erkannt wurden. Um das zu beheben, passen Sie die Eigenschaften des Felds so an, dass solche Zeichen richtig interpretiert werden. Wenn ein Feld beispielsweise nur Zahlen enthält, setzen Sie den Datentyp auf Number. Dadurch wird zum Beispiel verhindert, dass die Zahl “1” als “l” (kleines L) oder “I” (großes i) erkannt wird.