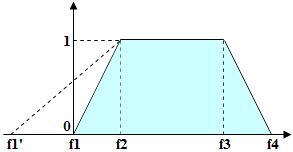
A Fuzzy interval is a tool that enables the program to assess the quality of a hypothesis based on its length. A fuzzy interval may be measured in units of length (dots, millimeters, etc.) or in characters (in the case of lines). For a fuzzy interval, four values must be specified which determine the possible and optimal range of values. For the purpose of simplification, an easy-to-use fuzzy interval editor is provided in the program.
Suppose you have a fuzzy interval {f1,f2,f3,f4} and the length of the detected string (in characters, or dots for a detected space) is L. If the length L is in the range from f2 to f3 (i.e. L>=f2 and L<=f3), the quality of the hypothesis is 1. If the length is in the range from f1 to f2, the quality of the hypothesis changes in direct proportion from 0 to 1 (Quality(f1) = 0, Quality(f2)=1). Similarly, if the length is in the range from f3 to f4, the quality of the hypothesis changes in direct proportion from 1 to 0 (Quality(f3) = 1, Quality(f4) = 0). If the length does not fall in the range from f1 to f4 (i.e. Lf4), the quality of the hypothesis is 0 (Quality(L) = 0). The quality of the hypothesis for the detected object is multiplied by the values of the Character count property, which is selected depending on the length of the detected object.
The quality of any chain of hypotheses for several elements is calculated by multiplying the hypotheses for each element in the chain. If the chain is sufficiently long and the quality estimates of the constituent hypotheses are too low due to the restrictions being too strict, the resulting quality of the entire chain may be too low as well.
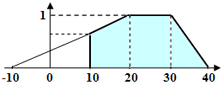
[-10,20,30,40}), you can do so directly in Hypothesis Evaluation by setting Value.Length >=10.
We do not recommend making the interval boundaries too strict. This is particularly important when processing images of varying quality. On some images for example, there may be spaces with letters due to the poor quality of the source document or the particular scanning options. In this case, the program may interpret one character as several characters, which may lead to a drastic decrease in the quality of the hypothesis if the interval was overly strict. As a result, the program may discard that hypothesis (which could have been correct in essence) and select a different one. For this reason, if you need to select between hypotheses by comparing their lengths, this should be done using additional conditions in Hypothesis Evaluation.