Documents with unconfirmed labeling are excluded from test results. Reference labeling generated automatically from predicted labeling is unconfirmed until you copy predicted labeling to reference using the Copy Predicted Labeling to Reference shortcut menu command. Check the labeling status on the Documents tab; confirm labeling on the Fields tab.
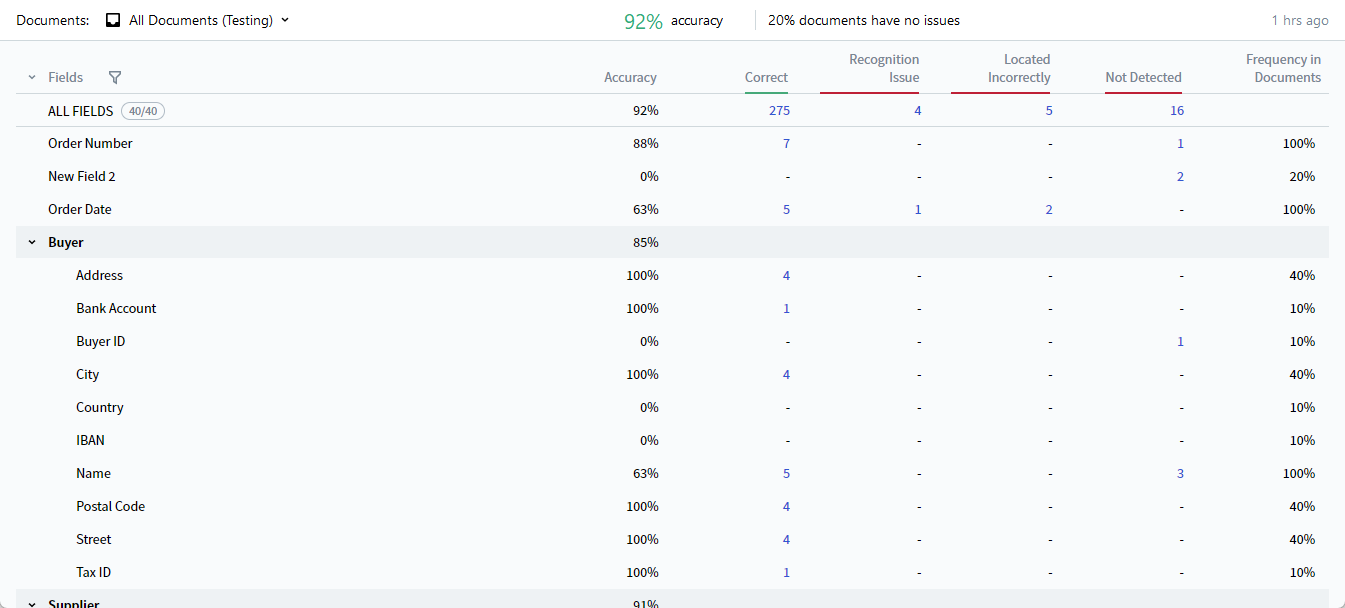
Field extraction statistics
The following statistics are available per field and aggregated in the ALL FIELDS row:| Column | Description |
|---|---|
| Accuracy | Percentage of correctly extracted values. |
| Correct | Number of field instances whose extracted value matched the reference value. |
| Recognition Issues | Number of field instances detected in the document but not recognized correctly. |
| Located Incorrectly | Number of field instances whose regions were detected in locations different from those specified in the labeling. |
| Not Detected | Number of undetected field instances. |
| Frequency in Documents | Percentage of documents containing the field. |
Comparison mode
Click any value in the Correct, Recognition Issues, Located Incorrectly, or Not Detected column to switch to comparison mode, which displays the reference and predicted labeling side by side on the document image. This helps you spot errors in reference labeling and identify problem fields that may need the activity reconfigured.Activity-specific statistics
Field extraction statistics are also available for individual activities on the Results tab in the Activity Editor. Activity statistics cover only the fields extracted by that activity. Use them to evaluate whether each activity is set up correctly and improve overall extraction quality.Related topics
Documents tab
Upload documents and organize them into sets.
Fields tab
Create skill fields and label documents.
Activities tab
Build the document processing flow.