Die letzte Instanz einer benannten Entität finden
Regel zum Extrahieren der letzten Organisationseinheit
Beispiel
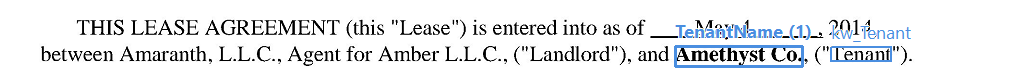
Extrahieren eines Geldbetrags, der sowohl ausgeschrieben als auch als Zahl angegeben ist
Regel zum Extrahieren eines Geldbetrags
Beispiel

Segmente mithilfe von Schlüsselwörtern finden
Regel zum Extrahieren von Überschriften der zweiten Ebene in das Suchelement kw_Heading2
Regel zum Extrahieren des Segments in das Element „Segmentsuche“
Beispiel

kw_Heading2 extrahiert. Anschließend wird der Text zwischen jeweils zwei aufeinanderfolgenden Vorkommen des Suchelements kw_Heading2 in eine Instanz des Suchelements Segment extrahiert.
Gruppierung der Informationen zu jeder Entität
- Nach Organisationsnamen suchen, für jeden gefundenen Namen eine neue Instanz des Gruppensuchelements
Party_Grouperstellen und dessen untergeordnetes Suchelement mit dem Namen „Organization_Name“ ausfüllen. - Nach der Adresse und der Rolle suchen, die höchstens, sagen wir, 20 Token von jeder Instanz des Organisationsnamens entfernt sind, die Instanz von
Party_Groupaufrufen, die das übergeordnete Element des Organisationsnamens ist, und die untergeordneten Suchelemente „Address“ und „Role“ in dieser Instanz ausfüllen.
Regel zum Extrahieren des Suchelements „Organization_Name“
Regel zum Extrahieren des Suchelements „Address“
Regel zum Extrahieren des Suchelements „Rolle“
Beispiel


Datum und Uhrzeit gemeinsam finden
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?). Anschließend suchen wir nach einer in der Nähe befindlichen benannten Entität Date. Abschließend verketten wir die gefundenen Token-Sequenzen und weisen das Ergebnis einem Suchelement namens „TimeAndDate“ zu.
Regel zum gemeinsamen Extrahieren von Datum und Uhrzeit
Beispiel
