Static Text ist ein Element in einem FlexiLayout, das einen vordefinierten Text beschreibt. Der Text kann aus einem Wort oder einer Wortgruppe bestehen. Wortgruppen unterscheiden sich von Wörtern dadurch, dass sie mindestens ein Leerzeichen enthalten. Eine Wortgruppe kann sich über mehrere Zeilen erstrecken.
Static-Text-Elemente werden im FlexiLayout-Baum mit  gekennzeichnet.
Das Programm verwendet Static-Text-Elemente, um nach statischem Text zu suchen, d. h. nach Text, der im Voraus bekannt ist. Dabei betrachtet das Programm Recognized Words- und Recognized Lines-Objekte, die während der Vorerkennung erkannt wurden und im Suchbereich des Elements liegen, als Kandidaten für statischen Text.
In der Regel enthalten alle oder viele Bilder im Batch statischen Text. Dabei kann es sich um die Überschrift des Dokuments handeln (zum Beispiel Invoice) oder um die Namen von Feldern (zum Beispiel Date, To:, From:).
Solche Objekte, die bei der Vorerkennung als Recognized Words erkannt wurden, werden üblicherweise als „Wegweiser“ verwendet, wenn nach beliebigem Text gesucht wird, der in die entsprechenden Felder eingetragen werden kann. So ist es beispielsweise naheliegend, neben dem statischen Text „Date“ ein Datum zu erwarten.”
gekennzeichnet.
Das Programm verwendet Static-Text-Elemente, um nach statischem Text zu suchen, d. h. nach Text, der im Voraus bekannt ist. Dabei betrachtet das Programm Recognized Words- und Recognized Lines-Objekte, die während der Vorerkennung erkannt wurden und im Suchbereich des Elements liegen, als Kandidaten für statischen Text.
In der Regel enthalten alle oder viele Bilder im Batch statischen Text. Dabei kann es sich um die Überschrift des Dokuments handeln (zum Beispiel Invoice) oder um die Namen von Feldern (zum Beispiel Date, To:, From:).
Solche Objekte, die bei der Vorerkennung als Recognized Words erkannt wurden, werden üblicherweise als „Wegweiser“ verwendet, wenn nach beliebigem Text gesucht wird, der in die entsprechenden Felder eingetragen werden kann. So ist es beispielsweise naheliegend, neben dem statischen Text „Date“ ein Datum zu erwarten.”
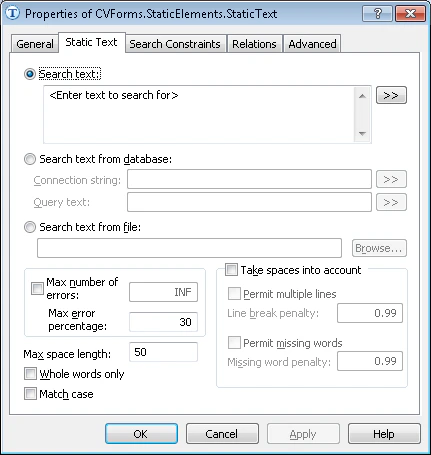
Eigenschaften des Static-Text-Elements
PURCHASEAGREEMENT ein.
Verwenden Sie einen vertikalen Strich (das Symbol |), um Varianten zu trennen. Wenn ähnliche Dokumente beispielsweise Bezeichnungen wie Contract oder Agreement haben können, geben Sie CONTRACT|AGREEMENT ein.
Varianten von Phrasen werden in geschweifte Klammern gesetzt und durch einen vertikalen Strich getrennt, in der Form { }|{ }. Sie können Varianten von Wörtern innerhalb von Phrasen angeben (die Option Leerzeichen berücksichtigen muss ausgewählt sein).
Wenn Sie zum Beispiel {SALE|PURCHASE AGREEMENT|CONTRACT}|{CUSTOMER|CLIENT APPLICATION} in das Feld Search text eingeben, sucht das Programm nach den folgenden Phrasen: sale agreement, purchase agreement, sale contract, purchase contract, customer application, client application.
Um lange Zeichenfolgen einzugeben, klicken Sie auf  , um ein separates Dateneingabefenster zu öffnen.
, um ein separates Dateneingabefenster zu öffnen.
Search text from database
SELECT beginnt, sucht die relevanten Felder in der Tabelle. Anschließend sucht das Programm im Bild nach dem Text, der im gefundenen Feld enthalten ist.
Die Verbindungszeichenfolge festlegen
Geben Sie im Feld Connection string die Verbindungszeichenfolge der Datenbank ein, oder klicken Sie auf , um das Standarddialogfeld für die Datenbankverbindung zu öffnen. Die Abfrage eingeben
Geben Sie im Feld Query text die Abfrage ein. Sie können auch auf klicken, um ein separates Dateneingabefenster zu öffnen. Maximale Anzahl von Fehlern
Leerzeichen berücksichtigen
Empfehlungen zum Erstellen eines Static-Text-Elements
-
Um sicherzustellen, dass der ausgewählte statische Text auf allen Bildern zuverlässig erkannt werden kann, prüfen Sie die Ergebnisse der Vorerkennung, indem Sie für Wörter bzw. Wortgruppen auf
 bzw.
bzw.  klicken. Vergewissern Sie sich, dass die Buchstaben korrekt zu Wörtern und die Wörter korrekt zu Zeilen gruppiert sind.
klicken. Vergewissern Sie sich, dass die Buchstaben korrekt zu Wörtern und die Wörter korrekt zu Zeilen gruppiert sind.
-
Wählen Sie nach Möglichkeit statischen Text in größerer Schrift, der auch bei Scans geringer Qualität unverändert bleibt oder bei dem die Anzahl der OCR-Fehler vorhersehbar ist.
-
Wenn die Dokumente nur statischen Text in kleiner Schrift enthalten, der bei der Vorerkennung nicht zuverlässig erkannt werden kann (d. h. wenn Anzahl und Art der Fehler von Bild zu Bild stark variieren), beschreiben Sie solche Textfragmente als Object Collection mit den ausgewählten Optionen Text und Punctuation mark und nicht als Static Text.
Möglicherweise müssen Sie auch die Option Picture auswählen. Klicken Sie dazu in der Symbolleiste auf
 (Raw Objects) und wählen Sie das entsprechende Objekt im Bild aus. Der Objekttyp wird in der Zeile DataType des Fensters Properties angezeigt.
(Raw Objects) und wählen Sie das entsprechende Objekt im Bild aus. Der Objekttyp wird in der Zeile DataType des Fensters Properties angezeigt.
-
Wählen Sie möglichst eindeutige Fragmente statischen Texts aus, um Fehltreffer zu vermeiden und die zusätzlichen Suchbedingungen auf ein Minimum zu beschränken.
-
Wenn es sowohl einwortige Namen gibt (die Sie mithilfe von Static-Text-Elementen finden möchten) als auch mehrwortige Namen, die dieselben Wörter wie die einwortigen Namen enthalten, erstellen Sie zuerst die Elemente für die mehrwortigen Namen. So verhindern Sie, dass das Programm einwortige Namen innerhalb mehrwortiger Namen fälschlich erkennt.
Empfehlungen für Chinesisch, Japanisch und Koreanisch
Für diese Sprachen ist eine Suche nach ganzen Wörtern nicht verfügbar, da Texte in diesen Sprachen oft nicht explizit in Wörter unterteilt sind.
SuggestOnlySimilarChars auf false gesetzt.