発行日の抽出
Date field を追加する
- Fields タブで Manage Fields ダイアログを開き、このアクティビティで使用する “Date” field を選択します。Save をクリックします。
- Search Elements タブに移動します。“Date” field 用の Date 型 search element が自動的に作成され、マッピングされています。
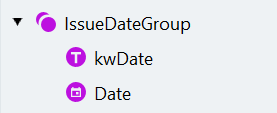
kwDate ラベルを含む IssueDateGroup を作成する
- “IssueDateGroup” という名前の Group search element を作成し、オプションに設定します。
- グループ内に “kwDate” という名前の Static Text 要素を追加します。これにより、実際の日付の位置を特定する手がかりとなるラベルを見つけます。
- この document class にはオランダ語またはフランス語の文書が含まれるため、Text to find ダイアログでラベルテキストの候補を別々の行に入力します。1 行目に “Date”、2 行目に “Datum” を入力します。
- Search for parts of words オプションを無効にします。
Date 要素の search area を設定する
- 要素の作成時に自動的に追加された Nearest to 関係を削除します。
- 検索対象の要素に最も近い要素として “kwDate” 要素を選択します。
- 日付はキーワードの右側または下側に配置されることがあります。“kwDate” 要素の下の search area を指定します。
- search area には、キーワードがある行も含める必要があります。要素名の右側にある下側境界アイコンをクリックし、Top Boundary of Region を選択します。行の高さがそろっていない場合があるため、search area が行の少し上まで広がるように Below の値を -10 に設定します。
病欠日付の抽出
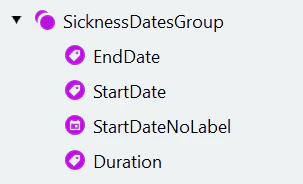
SicknessDatesGroup と EndDate 要素を作成する
- “SicknessDatesGroup” という Group 要素を作成します。要素はオプションにします。
- 開始日の静的テキストは省略されることがあるため、まず終了日を検索します。“EndDate” という Key value 要素を作成して設定します。
- Text to find field に “au”、“jusqu’au”、“tot en met” を各行に入力します。
- Gap between key and value オプションを無効にします。
- 値の型を Date に設定します。
StartDate要素のコピーを作成します
- “EndDate” 要素をコピーして貼り付け、名前を “StartDate” に変更します。
- Text to find を調整します。今回は “du” または “van” という単語を検索します。
- Match をクリックし、Advanced Designer で日付が正しく見つかったことを確認します。
開始日ラベルのない文書に StartDateNoLabel 要素を追加します
セット内の2番目のドキュメント (“BE-NL 02.png”) を選択します。このドキュメントには、日付に加えて病気休暇期間に関する情報も含まれていることがわかります。また、このドキュメントでは開始日にラベルがありません。まず、開始日を抽出するための追加の要素を設定します。
- “StartDateNoLabel”という名前のDate要素を作成します。
- 日付フォーマットを「日、月、年」に設定します。
- 要素の検索範囲を”EndDate”の左側に指定します。
- 終了日と同じ行にある日付を見つけます。その行に検索範囲を限定するには:
- 要素が”EndDate”の上かつ下に位置するよう指定します。
- 対応するリレーションの近くにある下端境界と上端境界のアイコンをクリックして、検索の基準となる要素の境界を変更します。検索範囲は、“EndDate”の上端より下、かつその下端より上に配置されるようにします。このように設定すると、検索範囲を”EndDate”がある行に限定できます。
- “StartDate”要素が見つかっている場合は、この要素を検索する必要はありません。PropertiesペインのUnder what conditions領域で、Do not find element ifの右側にあるプラスアイコンをクリックします。
- ドロップダウンメニューで**Other Element Is Found…**を選択し、次に”StartDate”要素を選択します。
- “StartDate”要素に戻ります。これが見つからない場合、後続の要素のhypothesis qualityが低下し、対応する領域はfieldに渡されません。これを避けるには、PropertiesペインのUnder what conditions領域に移動し、この要素のMin. hypothesis qualityを1に設定します。
病気休暇の期間を抽出する
- “Duration” という名前の Key value 要素を作成します。
- Text to find フィールドに、文字列 “durée de :” と “Gedurand” を貼り付けます。
- Gap between key and value オプションを無効にします。
- 値の型を Character String に設定し、文字セットを編集します。数字だけを含めるようにしてください。
- 最大文字数を 3 に設定します。
- Match をクリックし、値が正しく見つかったことを確認します。
fieldを作成してマッピングする
- Manage Fieldsダイアログを開き、“Duration”という名前の新しいText fieldを作成します。データ型をNumberに変更します。
- このアクティビティで使用する”Start Date”フィールドと”End Date”フィールドを選択します。Saveをクリックします。
-
fieldをマップします。
“Start Date”フィールドには、このフィールドにRegionを渡す可能性のあるsearch elementが2つあります。コードを使用して各要素が見つかったかどうかを確認し、対応するRegionをフィールドに渡します。Get region fromリストでCodeを選択し、次のコードをCode Editorに貼り付けます。
Name Search element End Date EndDate Duration Duration Start Date コードで設定 - フィールドを有効にしたときに自動的に作成された要素を削除します。
患者データの抽出
患者情報を含む段落を特定します
- “PatientParagraphGroup” という名前の Group 要素を作成します。要素はオプションに設定します。
- 患者データの前には、医師が患者を診察したことを述べる文があります。この文を特定するために、その中に含まれる語句を検索します。“kwExamined” という名前の Static Text 要素を作成します (Text to find: “interrogé” または “ondervraagd”) 。
- 患者データの後には、医師が患者に何ができないかを述べる結論があります。この結論を特定するために、“kwIncapable” という名前の Static Text 要素を作成します (Text to find: “incapable”、“niet in staat”、“onbekwaam”、“déclare que :”) 。
-
患者データを含む段落は、今見つけた 2 つのキーワードの間にあります。次の設定で Paragraph 要素を作成します。
プロパティ 値 名前 NameAddressParagraph 最小行数 1 最大行数 4 最小行幅 200 検索領域 ”kwExamined” の下、“kwIncapable” の上、“kwExamined” に最も近い - Match をクリックします。
PatientGroup と AdditionalDataGroup を作成する
- 段落からデータを抽出するために、“PatientGroup” という名前の任意のグループを作成します。
- まず、見つけやすく、一部のドキュメントにのみ存在する追加データを抽出します。“PatientGroup” グループ内に、“AdditionalDataGroup” という名前の任意のグループを作成します。
- 患者の生年月日を抽出するには、“BirthDate” という名前の Date 要素を作成します。ドキュメントにデータがない場合でもこの要素を抽出できるように、Min. hypothesis quality を調整します。
-
“NameAddressParagraph” 内の検索領域を指定するには、Code Editor を使用します。
-
患者名の後に、通常はかっこで囲まれた 11 桁の数値 ID が続く場合があります。この ID を抽出するには、次の設定で Character String 要素を作成します。
プロパティ 値 名前 PatientID メソッド Regular Expression 正規表現 ("("|)N{11}(")")文字数 {11, 11, 13, 13}語の一部を検索 無効 Regular Expression Editor では固有の構文を使用します。詳しくは、Character String トピックを参照するか、エディターで Syntax help をクリックしてください。
患者の氏名を検索する
- “PatientGroup” グループ内に、“NameGroup” という名前のオプション グループを作成します。
- まず、一部のドキュメントに含まれるラベルを除外します。“NameLabel” という名前の Static Text 要素 (検索するテキスト: “Nom, prénom du patient :” または “Patiente”) を作成します。大文字と小文字を区別 オプションを有効にし、最小仮説品質 を 1 に変更します。
-
名前は先頭が大文字の 2 語または 3 語で構成されると見なし、正規表現を使用して検索します。次の設定で Character String 要素を作成します。
プロパティ 値 名前 Name メソッド 正規表現 正規表現 (([A-Z])(C|"-"){1-}s)許容エラー 0% 単語数 {2, 2, 3, 3}語の一部を検索 無効 検索領域 ページ上端に最も近い位置、“PatientID” と “NameLabel” を除外 Code Editor の Search Conditions セクション RSA: PatientParagraphGroup.NameAddressParagraph.Rects;
患者の住所を検索する
患者の住所が存在する場合、その住所は、これまでに見つかったすべての要素より下にある “NameAddressParagraph” 内にあります。“PatientGroup” グループで、次の設定で Paragraph 検索要素を作成します。
検索要素の構造は次のようになります。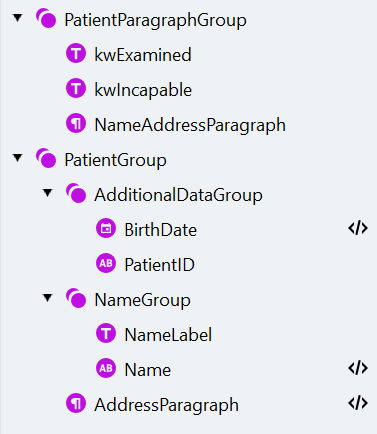
| プロパティ | 値 |
|---|---|
| 名前 | AddressParagraph |
| 検索領域 | ”Name”、“BirthDate”、“AdditionalDataGroup” の下 |
| Code Editor の Search Conditions セクション | RSA: PatientParagraphGroup.NameAddressParagraph.Rects; |
患者のfieldをマッピングする
-
Manage Fieldsダイアログを開き、このアクティビティで使用する「Patient」グループ内の以下のfieldを選択し、次のようにsearch elementにマッピングします。
名前 検索要素 氏名 PatientGroup -> NameGroup -> Name 生年月日 PatientGroup -> AdditionalDataGroup -> BirthDate 保険者番号 PatientGroup -> AdditionalDataGroup -> PatientID 住所 PatientGroup -> AddressParagraph - fieldを有効にした際に自動作成された要素を削除します。
医師データの抽出
SignatureGroup を作成して署名を特定する
- “SignatureGroup” という名前の Group 要素を作成します。この要素はオプションにします。
- 多くの文書には署名ラベルが含まれています。これを見つけるため、“kwSignature” という名前の Static Text 要素を作成します (Text to find: “Signature” または “handtekening”) 。
-
署名そのものを特定するには、次の設定で Object Collection 要素を作成します。
Property Value 名前 Signature 型 Picture 最小幅 15 最小高さ 15 最大幅 600 最大高さ 350 search area ”kwSignature” の上境界より下、“kwSignature” に最も近い
医師の ID を特定する
- “DoctorGroup” という名前の Group 要素を作成します。この要素はオプションにします。
-
まず、形式が厳密に決まっているため正規表現で定義できる医師IDを検索します。次の設定で Character String 要素を作成します。
Property Value 名前 DoctorID メソッド Regular Expression 正規表現 N{1-1}n{1-1}N{5-5}n{1-1}N{2-2}n{1-1}N{3-3}文字数 {13, 13, INF, INF}search area ページ上端に最も近い -
文書によっては医師の肩書きも含まれています。これを特定して、医師データを含む段落から除外します。次の設定で Static Text 要素を作成します。
Property Value 名前 kwDoctorTitle Text to find Cachet du prescripteur, Médecin, Stempel van de voorschrijver, Identification du médecin (各語句を新しい行に入力) Match case Enabled 許容エラー 10% ヌル仮説の品質 1 -
医師データを特定するには、次の設定で Paragraph 要素を作成します。
Property Value 名前 DoctorInformationParagraph テキスト配置 Left 行数 4 - 6 search area ”kwDoctorTitle” の下、“DoctorID” に最も近い、“IssueDateGroup” を除外

病欠証明書の種類を抽出する
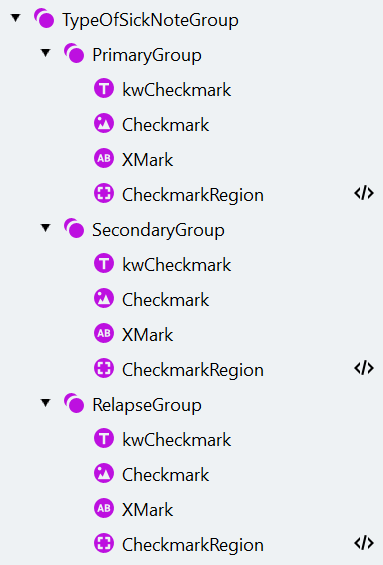
TypeOfSickNoteグループとPrimaryGroupを作成する
- Group 要素を作成し、“TypeOfSickNote” という名前を付けます。この要素は任意にします。
- 各チェックマークを抽出するには、同じアルゴリズムを使用します。1 つの要素グループを設定してから、それをコピーし、必要なプロパティを調整します。
- “PrimaryGroup” という名前の任意のグループを作成します。
- まず、キーワードの位置を特定します。“kwCheckmark” という名前のStatic Text 要素を作成します (Text to find: “le début de” または “Eerste ongeschiktheid”) 。
- この要素を必須にします。キーワードが見つからない場合、Advanced Designer は対応するチェックマークを検索しません。
Checkmark、XMark、CheckmarkRegion の各要素を作成する
次に、チェックマークを検索します。まず実際のチェックマークを検索し、次に文字
“CheckmarkRegion” 要素では、Code Editor の Search Conditions セクションに次のコードを貼り付けます。
"x" を含む文字列を検索します。チェックマークまたは X マークに対して見つかった矩形を、field にマッピングする Region search element に割り当てます。Primary チェックマークを特定するには、次の要素を作成します。| Property | Value |
|---|---|
| Object Collection search element: | |
| Name | Checkmark |
| Type | Checkmark |
| Maximum height | 100 |
| Search area | ”kwCheckmark” の top boundary より下、Below value = -15、“kwCheckmark” の左、“kwCheckmark” の bottom boundary より上、Above value = -15、“kwCheckmark” に最も近い |
| Min. hypothesis quality | 1 (チェックマークが見つからなかった場合に hypothesis chain quality が低下しないように、この設定を調整します) |
| Character String search element: | |
| Name | XMark |
| Method | Characters |
| Character set | []|Xx |
| Word count | {1, 1, 1, 1} |
| Character count | {1, 1, 3, 3} |
| Search for parts of words | Disabled |
| Search area | ”kwCheckmark” の top boundary より下、Below value = -15、“kwCheckmark” の左、“kwCheckmark” の bottom boundary より上、Above value = -15、“kwCheckmark” に最も近い |
| Under what conditions | ”Checkmark” が見つかった場合は要素を検索しない |
| Region search element: | |
| Name | CheckmarkRegion |
SecondaryGroupとRelapseGroupを作成する
- “PrimaryGroup” のコピーを作成し、名前を “SecondaryGroup” に変更します。次に、その “kwCheckmark” 要素の検索対象テキストを “prolongation”、“verlenging” に変更します。
- ドイツの病欠証明書には2種類ありますが、オランダとベルギーの病欠証明書には3種類あります (‘relapse’ が追加の種類です) 。“PrimaryGroup” グループのコピーをもう1つ作成し、名前を “RelapseGroup” に変更します。
- その “kwCheckmark” 要素の検索対象テキストを “Herval” に変更し、文中に現れる単語を除外するため、大文字と小文字を区別 オプションを有効にします。
アクティビティをテストする
次のステップ
ステップ 9. ビジネスルールを設定する
抽出されたfieldの値を検証して正規化するためのビジネスルールを追加します。
チュートリアルの概要
チュートリアルの冒頭に戻ります。