メソッド
文字
文字セットの設定
1
文字エンコーディング規格を選択
ドロップダウンリストで、Code Page フィールドまたは Unicode Subrange フィールドから適切な文字エンコーディング規格を選択します。
2
文字を選択
下の表で該当する文字を選択します。
3
選択した文字を確認
選択した文字は Selected characters フィールドに表示されます。キーボードで文字セットを指定することもできます。
4
文字の割合を指定
Portion in text, % フィールドで、検索対象のテキストに含まれる文字の割合 (0~100) を指定します。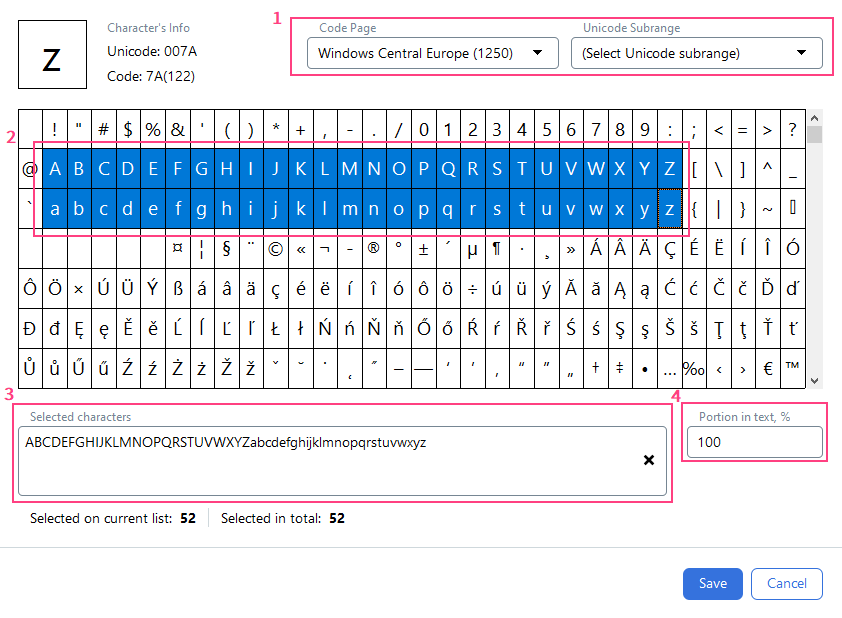
正規表現
正規表現のアルファベット
正規表現の例
拡張正規表現
[% and %]) で追加機能を囲んだ正規表現です。拡張正規表現には、次の追加機能があります。
- 角かっこ内の1文字以上に、一般的なOCR誤認識が補われます。たとえば、
[%S%]では S、$、5 が許容される場合があります。 - 一般的な文字セットとOCR誤認識を表す、
[%...%]内の特別な語:- LETTERS — ラテン大文字、およびラテン大文字として一般的に認識される文字。
- DIGITS — 数字、および数字として一般的に認識される文字。
- LETTERSANDDIGITS — ラテン大文字、数字、およびラテン大文字や数字として一般的に認識される文字。
[%DIGITS%]{9} は、9文字連続の数字、または数字に対する一般的なOCR誤認識を指定します。例: “OI234Sb7B9”。
追加プロパティ
- 許容エラー は、認識エラーの最大許容割合を指定します。言い換えると、定義された文字セット外の文字が全体の文字数に占める最大許容割合を示します。オブジェクトの仮説は、その認識エラー率が指定値を超えていない場合にのみ立てられます。
- 単語数 は、検索対象テキストに含まれる単語の最小数と最大数を指定します。
- 文字数 は、検索対象テキストに含まれる文字の最小数と最大数を指定します。
- 語の一部を検索 は、仮説に単語の断片を許可するかどうかを指定します。単語の断片を含む仮説を除外し、完全一致の単語のみを検索する必要がある場合は、このオプションを無効にします。
詳細プロパティ
- 埋め込み仮説を許可 は、検索領域内の文字を用いて、交差および埋め込みの仮説を含むあらゆる可能な仮説を生成できるようにします。
- 最大スペース長 は、検出されたオブジェクト内の空白の最大長を指定します。
- テキストの向き は、検索対象のテキストの向きを指定します。既定では、このアクティビティは水平方向のテキストのみを検索し、回転したテキストについては仮説を作成しません。特定の向きに回転したテキストのみを検出し、他の向きのテキストを無視したい場合は、時計回り または 反時計回り のいずれか一方のみを選択してください。向きに関係なくテキストを検出したい場合は、利用可能なすべてのオプションを有効にしてください。
- 単語の検出方法 は、行を単語に分割する方法を指定します。自動 (認識前) にするか、隣接する文字間の空白が 最小単語間スペース に入力した値以上の場合に行を単語に分割する (単語間スペース) かを選択します。