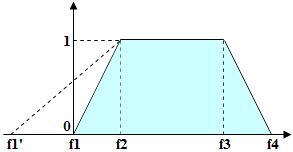
ファジー区間は、仮説の長さに基づいてその品質を評価するためのツールです。ファジー区間は、長さの単位 (ドット、ミリメートルなど) または文字数 (行の場合) で測定できます。ファジー区間では、可能な範囲と最適な範囲を定める4つの値を指定する必要があります。簡便化のため、プログラムには使いやすいファジー区間エディタが用意されています。
ファジー区間が{f1,f2,f3,f4}で、検出された文字列の長さ (文字数、またはスペースが検出された場合はドット数) がLであるとします。長さLがf2からf3の範囲にある場合 (すなわち L >= f2 and L <= f3) 、仮説の品質は1です。長さがf1からf2の範囲にある場合、仮説の品質は0から1へと比例的に変化します (Quality(f1) = 0, Quality(f2) = 1) 。同様に、長さがf3からf4の範囲にある場合、仮説の品質は1から0へと比例的に変化します (Quality(f3) = 1, Quality(f4) = 0) 。長さがf1からf4の範囲に含まれない場合 (すなわち L < f1 or L > f4) 、仮説の品質は0です (Quality(L) = 0) 。検出されたオブジェクトに対する仮説の品質は、検出されたオブジェクトの長さに応じて選択される Character count プロパティの値と乗算されます。
複数要素に対する仮説の連鎖の品質は、連鎖内の各要素に対する仮説を乗算して算出されます。連鎖が十分に長く、構成する仮説の品質評価が制約の厳しさゆえに低すぎる場合、連鎖全体の最終的な品質も低くなり得ます。
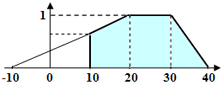
[-10,20,30,40}である) 、Hypothesis Evaluation で Value.Length >= 10 を設定することで直接指定できます。
区間境界を厳格にし過ぎないことを推奨します。これは、品質がさまざまな画像を処理する場合に特に重要です。例えば一部の画像では、元のドキュメントの品質不良や特定のスキャン設定により、文字の間に空白が生じることがあります。この場合、プログラムは1文字を複数文字として解釈する可能性があり、区間が過度に厳しいと仮説の品質が急激に低下します。その結果、本来は正しかった仮説が破棄され、別の仮説が選択されることがあります。このため、仮説の長さを比較して選択する必要がある場合は、Hypothesis Evaluation で追加の条件を用いて行ってください。