開始する前に
1
Activity Editor でアクティビティを開く
- Activity Editor で “病欠証明書 DE” アクティビティを開きます。
- ドキュメントセットからドキュメントを1つ選択します。
2
要素の詳細プロパティを有効にする
要素プロパティの詳細モードが有効になっていることを確認します。このモードを切り替えるには、Properties ペインのアイコンをクリックします。
患者データの抽出
1
PatientDataArea グループを作成する
- Create Element をクリックし、ドロップダウンリストから Group 要素を選択します。名前を “PatientDataArea” に変更します。
- Under what conditions セクションで、Element is の値を Optional に変更します。
2
Static Text 要素で患者ラベルを見つける
ドイツの文書では、患者の氏名と住所を含む段落は、常に “Name, Vorname …” というラベルの field 内にあります。このテキストを文書上で見つけ、それを基準にして、抽出したいデータを検索します。
- Create Element をクリックし、ドロップダウンリストから Static Text 要素を選択します。名前を “kwPatientTitle” に変更します。
- Properties ペインの Text to find field に “Name, Vorname” と入力します。
- Match をクリックします。処理が完了すると、文書の下に Tree of Hypotheses が表示されます。
- Advanced Designer が静的テキストを正しく見つけたことを確認してください。要素名の横に緑色の点が表示されていれば、照合成功です。
- Tree of Hypotheses で要素名をクリックすると、文書上の該当する領域が紫色のフレームで囲まれて表示されます。
要素が見つからなかった場合は、名前の横にオレンジ色の点が表示され、文書画像の該当箇所がオレンジ色のフレームで囲まれます。要素の仮説の品質は、チェーン内の後続要素の状態やチェーン全体の品質に影響する点に注意してください。詳細については、Optimization of Hypothesis Matching を参照してください。
3
Separatorを使って下側の境界を特定する
Separator 要素を使用して、患者の氏名と住所を含むセルの下境界を見つけます。
- グループに Separator 要素を追加し、“SeparatorBottom” という名前を付けます。最小長を 200 に設定します。
- 要素を右クリックし、コンテキストメニューから Match Element を選択します。Tree of Hypotheses には多数の緑色の点が表示されます。これらは、検索条件に一致するさまざまな区切り線に対応しています。各点をクリックすると、画像上の対応するオブジェクトを確認できます。
- 検索条件をさらに絞り込むため、区切り線の検索領域を指定します。
- Match をクリックして、アンカー要素として使用する “kwPatientTitle” 要素を見つけます。
- Properties ペインの Where to search セクションで、Draw on Image をクリックします。
- ドキュメント上の “kwPatientTitle” 要素を選択し、下向き矢印アイコンをクリックしてキーワードの下側を検索領域として指定します。次に、最も近いアイコンをクリックして、キーワードに最も近い区切り線を検索します。
- Match をクリックし、Advanced Designer が “kwPatientTitle” 要素の下にある区切り線を検出したことを確認します。
4
氏名と住所が記載された段落を探します
患者データについては、ラベルと区切り線が信頼できる参照要素です。ただし、印字品質が低すぎると、ラベルのテキストが認識されなかったり、区切り線が検出されなかったりすることがあります。良好な抽出結果を得るには、ラベルと区切り線の間にある段落を検索します。段落は均一なテキストブロックであるため、境界要素の一部が欠けていても検出できます。
- Paragraph の search element を作成し、“NameAddressParagraph” という名前を付けます。
- Text alignment を Left に変更します。
- 患者データは2行から5行にわたるため、Line count を 2 ~ 5 に指定します。
- Where to search セクションの Add メニューを使用して、段落の search area を指定します。この要素は、“kwPatientTitle” 要素の下、“SeparatorBottom” 要素の上に配置する必要があります。
- Match をクリックします。
5
PatientGroup を作成する
患者情報を抽出する検索要素をまとめるための、“PatientGroup” という名前の新しいグループ要素を作成します。
6
繰り返しグループ「NameGroup」を設定する
患者の名前は、1 行または 2 行にわたる場合があります。要素の複数のインスタンスを取得するには、繰り返しグループを使用します。
- 繰り返しグループ 検索要素を作成し、“NameGroup” という名前を付けます。最大繰り返し回数に 2 を指定します。要素はオプションにします。
-
検索範囲を “NameAddressParagraph” 段落に含まれる行のみに制限するには、文書画像の下にある Code Editor アイコンをクリックし、次のスクリプトを Search Conditions セクションの Code Editor に貼り付けます。
- 繰り返しグループ内に、1 行分の文字列を取得するための Character String 要素を作成します。“NameLine” という名前を付けます。
-
検索対象のテキストには、ラテン文字の大文字・小文字と、いくつかの句読記号が含まれる場合があります。2 つの文字セットを個別に設定します。
- 1 つ目のセットには、ラテン文字の大文字と小文字をすべて含めます。ダイアクリティカルマーク付きの文字を追加するには、Unicode サブレンジを変更するか、文字を Selected characters field に直接貼り付けます。
- 2 つ目のセットには、次の句読記号を含めます: ,-.()’. 文字列が句読記号だけにならないように、2 つ目のセットの Portion in text, % を 40% に設定します。
- Search for parts of words オプションを無効にします。
- “NameLine” 要素の検索範囲を指定します。“kwPatientTitle” 要素の下で、かつその最も近くに設定します。
- Match をクリックし、Tree of Hypotheses を確認します。2 つの文字列が見つかりますが、2 つ目の文字列には患者の住所が含まれています。
-
検索結果から住所を除外するには、スクリプト検索条件を追加します。
- “NameLine” 検索要素を選択し、Search Conditions の Code Editor を開きます。
-
次のスクリプトを貼り付けます。これは、1 行目にカンマと空白が含まれている場合、その行には氏名が含まれていると見なし、氏名が見つかった場合は繰り返しグループが 2 つ目のインスタンスの検索を停止することを前提としています。
- Match をクリックし、名前が正しく検出されることを確認します。
既定の設定では、どのセットにも含まれない文字を文字列に最大 30% まで含めることができます。これにより、一部の文字が誤って認識された場合や、セットに含まれていない場合 (ダイアクリティカルマーク付き文字など) でも、文字列を検出しやすくなります。この設定は、Properties ペインの Allowed errors の値を変更して調整できます。
7
「NameRegion」という Region 要素を作成する
繰り返しインスタンスを持つ要素には field をマッピングできないため、“NameGroup” インスタンスのすべての領域を含む補助的な Region 要素を作成します。
- “PatientGroup” グループに Region search element を作成し、“NameRegion” という名前を付けます。
-
Code Editor を開き、次のスクリプトを Search Conditions セクションに貼り付けます。
8
AddressRegion という Region 要素を作成する
患者の名前はすでに見つかっており、“NameAddressParagraph” 段落の残りの部分が住所です。住所を含む領域を指定するには、“NameAddressParagraph” 領域から “NameGroup” の矩形を除外します。“PatientGroup” グループに別の Region 要素を作成し、“AddressRegion” に名前を変更して、次のスクリプトを Search Conditions セクションの Code Editor に貼り付けます。search element の構造は次のようになります。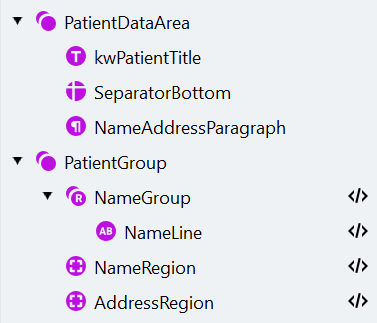
9
患者のfieldを作成し、マッピングする
Manage Fields ダイアログを開き、対応する field を作成し、以下のように検索要素にマッピングします。
新しい field 用に自動作成された検索要素を削除します。
病欠証明書の種類を抽出する
1
TypeOfSickNoteGroup と PrimaryGroup を作成する
「TypeOfSickNoteGroup」グループを作成します。その中に「PrimaryGroup」グループを作成します。両方のグループを任意にします。
2
PrimaryGroup を設定する
- 「PrimaryGroup」グループ内に、「kwCheckmark」という名前のStatic Text要素 (検索するテキスト: 「Erstbescheinigung」) を作成します。
- この要素は、前に検索した要素とは関係ありません。要素ツリー全体をマッチングする代わりに、「kwCheckmark」要素のコンテキストメニューで Match Element をクリックして、新しい要素だけをマッチングします。キーワードが正しく見つかっていることを確認してください。
- 次に、チェックマーク、バーコード、画像などのさまざまなグラフィックobjectを見つけるために使用されるObject Collection要素を使って、チェックマークを見つけます。
- 「Checkmark」という名前のObject Collection要素を追加します。
- Properties ペインの Type ドロップダウンリストで、Checkmark 以外のすべてのオプションを選択解除します。
- objectの最小の幅と高さを 30 に、最大の幅と高さを 130 に設定します。
- チェックマークの検索領域を「kwCheckmark」要素の左側に指定します。
-
チェックマークは、キーワードとほぼ同じ行にある必要があります。次のコードを Code Editor の Search Conditions セクションに貼り付けて、要素の上端と下端の境界がキーワードに対してどこに位置するかを指定します。
- Match をクリックします。
3
SecondaryGroup を作成して設定する
- 「PrimaryGroup」グループをコピーし、コピーの名前を「SecondaryGroup」に変更します。
- グループをコピーすると、そのプロパティとともにすべての要素もコピーされます。「SecondaryGroup」グループの「kwCheckmark」要素を選択し、検索するテキストを「Folgebescheinigung」に変更します。
- Object Collection検索要素は、検索範囲内にある条件に合うすべてのobjectのcollectionを見つけます。チェックマークが同じ行に配置されている場合、「SecondaryGroup」の「Checkmark」要素が Primary のチェックマークも見つけてしまうことがあります。これを避けるため、「SecondaryGroup」の「Checkmark」要素の検索領域から primary のチェックマーク (「PrimaryGroup」の「Checkmark」要素) を除外します。
- Match をクリックします。
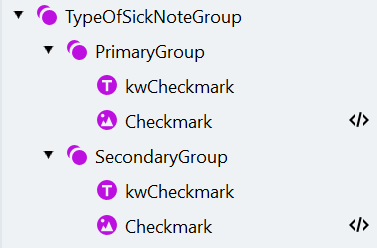
4
病欠証明書の種類のfieldを作成してマッピングする
Manage Fields ウィンドウを開き、対応するfieldを作成して、次のように検索要素にマッピングします。
新しいfield用に自動作成された検索要素を削除します。
医師データの抽出
1
DoctorAreaGroup と DataArea を作成
- “DoctorAreaGroup” という名前の Group 要素を作成します。この要素は任意とします。
- 探すボックスにはラベルが含まれています。これを見つけるために、“kwDoctorTitle” という名前の Static Text 要素を作成します (検索するテキスト: “Unterschrift des Arztes”) 。
- “DoctorAreaGroup” グループの中に、“DataArea” という名前のグループをもう 1 つ作成します。
2
境界を成す 4 つの Separator を追加
医師の情報と署名を含むボックスは、4 本のセパレーターの組み合わせによって構成されています。これらは “kwDoctorTitle” 要素の周囲に配置されています。ただし、“kwDoctorTitle” 要素が見つからなかった場合でも Advanced Designer がボックスを見つけられるように、要素を設定する必要があります。“DataArea” グループ内に、次のプロパティを持つ 4 つの Separator 検索要素を作成します。
4 つの要素すべてについて Fits entirely within search area オプションを無効にします。
3
BoxRegion の作成
“BoxRegion” という名前の Region 検索要素を作成し、検索領域を次のように指定します: “SeparatorRight” の左側、“SeparatorLeft” の右側、“SeparatorBottom” の上側、“SeparatorTop” の下側。この領域は 4 本のセパレーターで囲まれた範囲に対応しており、これを使用することで、署名と医師情報の検索領域を手動で指定する必要がなくなります。
4
DoctorGroup を作成する
署名要素と情報要素を格納するために、“DoctorAreaGroup” グループ内に、“DoctorGroup” という名前の新しいグループを作成します。
5
Signature の Object Collection を追加する
医師の署名を検出するために、“DoctorGroup” 内に次の設定を持つ Object Collection 要素を作成します。
6
DoctorInformation Paragraph の追加
ボックス内のテキスト情報を抽出するには、次の設定を持つ Paragraph 要素を作成します。
7
要素が見つかることを確認する
Match をクリックし、要素が正しく検出されていることを確認します。検索要素の構造は次のようになります: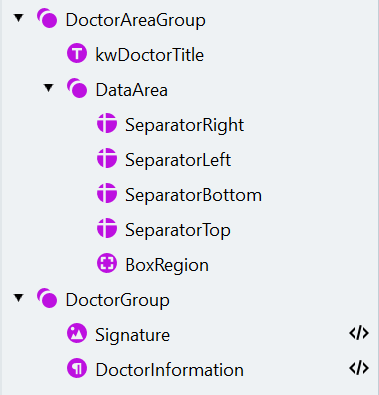
8
医師の field の作成とマッピング
Manage Fields ダイアログを開き、対応する field を作成して、次のように検索要素にマッピングします。
新しい field 用に自動的に作成された検索要素を削除します。
アクティビティをテストする
次のステップ
Step 8. 病欠証明書 BE-NL アクティビティを設定する
オランダとベルギーの病欠証明書向けに、Extraction Rules アクティビティを設定します。
チュートリアルの概要
チュートリアルの概要に戻ります。