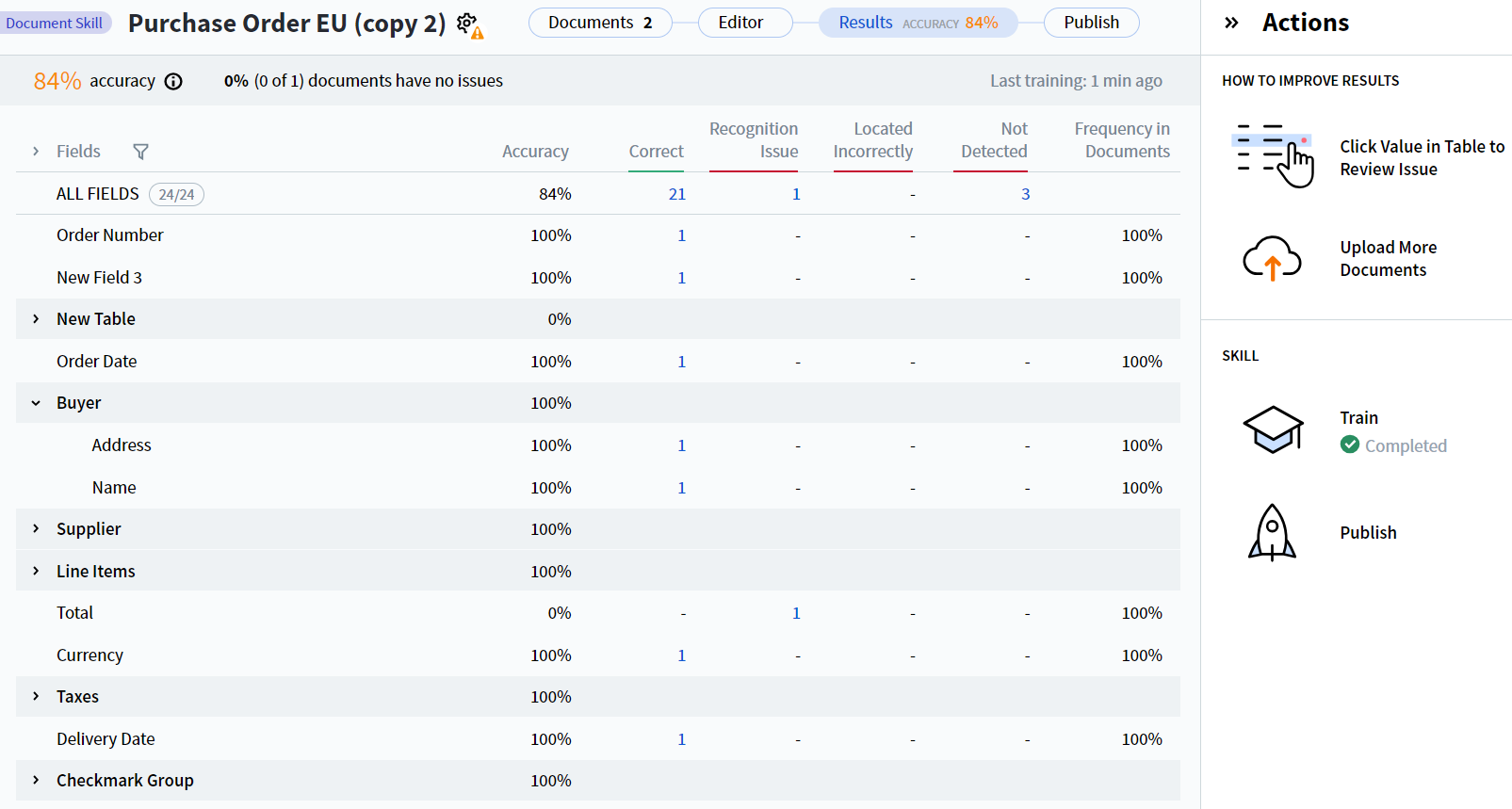
Document Skill Designer の Results タブには、Document skills の field 抽出に関する統計が表示されます。これらの統計を利用して、抽出品質の改善に役立てることができます。
skill で抽出されたすべての fields は、Fields 列に表示されます。group に属する fields は、group 名の付いた折りたたみ式のドロップダウンにまとめられます。
利用可能な field 抽出統計は次のとおりです。
-
Accuracy — 値が正しく抽出された fields の割合。field ごと、およびすべての fields 全体 (ALL FIELDS 行) について表示されます。
field ごとの精度は、次の式で計算されます。
ALL FIELDS 行でも同じ式を使用しますが、各項目はすべての fields を集計した値です。
-
Correct — 抽出値が参照値と一致した field インスタンスの数。
-
Recognition Issue — documents内では検出されたものの、正しく認識されなかった field インスタンスの数。
-
Located Incorrectly — ラベリング時とは異なる位置で領域が検出されたため、値が予測値と異なる field インスタンスの数。
-
Not Detected — 検出されなかった field インスタンスの数。
-
Frequency in Documents — 指定した field を含むdocumentsの割合。
既定では、すべての fields の統計が表示されます。絞り込むには、Fields 列の上部にあるフィルター icon をクリックし、表示する fields を選択します。
field 値と領域検出の両方について、Precision、Recall、F-measure など、さらに詳細な品質解析を行うには、Advanced Designer で skill を編集してください。詳細については、Advanced Accuracy Reports を参照してください。 これらの統計を本番環境の品質評価に適切に反映させるには、テストセットのdocuments分布を本番環境の分布に合わせる必要があります。たとえば、本番環境の請求書の 30% が特定のベンダーからのものである場合、テストセットでも約 30% をそのベンダーの請求書にする必要があります。さらに、blind set (学習や過去のテストに使用していないdocuments) を使用すると、結果をより確実に検証できます。
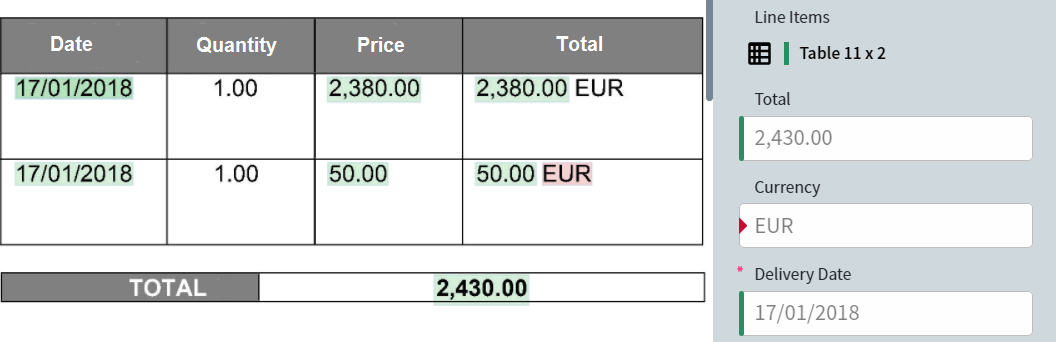
Order Date fieldのRecognition Issue列の値をクリックすると、Order Dateに認識上の問題があったdocumentsのみを表示するタブが開きます。
- Reference — Skill の設定時 (学習前) に作成された参照ラベル付けと、それを使用して抽出された field の値を表示します。このモードでは、field の値と領域を編集できます。
- Predicted — documents の処理時に取得された field の値と領域を表示します。編集はできません。
- Difference — 参照ラベル付けと予測ラベル付けの差異を表示します。同じ値と領域は緑色で表示され、異なるものは赤色で表示されます。編集はできません。
ツールバー上の対応するタブをクリックして、モードを切り替えます。
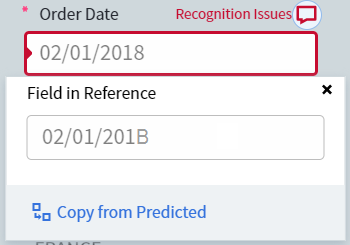
設定時にfieldのラベル付けを誤っていても、学習中に正しく処理された場合は、参照ラベル付けを更新できます。Difference モードに切り替え、誤ってラベル付けされたfieldの値の上にあるアイコンをクリックします。
Field in Reference ボックスには、参照ラベル付けを使用して抽出された値が表示されます。Copy from Predicted をクリックすると、誤った値を処理時に抽出された値に置き換えられます。
認識問題とは、1文字以上が正しく認識されなかったことを意味します。これを修正するには、そのような文字が正しく解釈されるようにfieldのプロパティを調整します。たとえば、fieldに数字のみが含まれる場合は、データ型を Number に設定します。これにより、たとえば数字の “1” が “l” (小文字のL) や “I” (大文字のI) として認識されるのを防げます。