Method
Method specifies the search method for the text. The following 2 methods are available:Characters
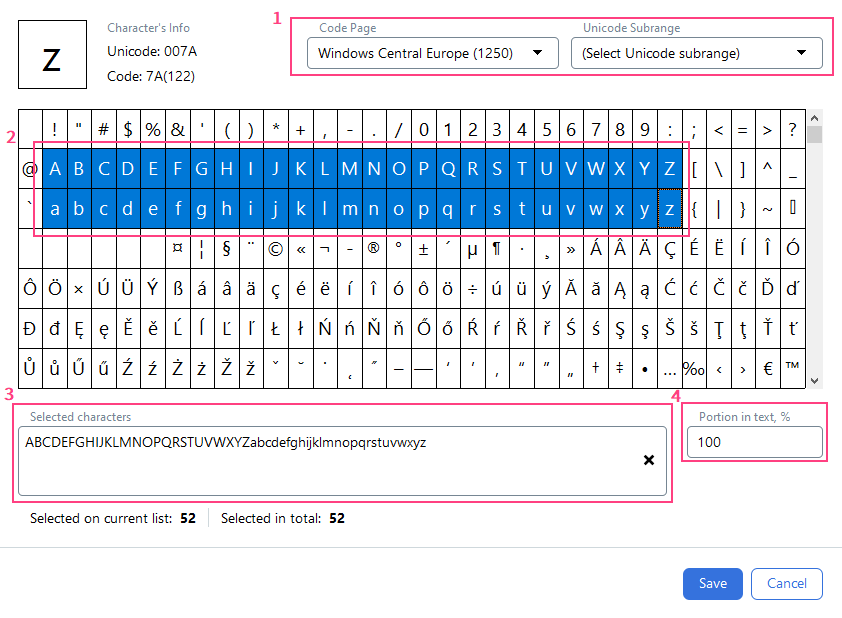
Characters describes the text using a specified character sets, which is a collection of characters permitted to be in the sequence that is being searched for. This method is used when the character sequence format cannot be described using a regular expression, or if the image quality is not high enough, resulting in recognition errors. Several character sets can be specified for a Character String element, however, these character sets cannot contain characters common to several at the same time. If the format of the text is not known, allowed character sets are not specified, and all possible characters are considered during the search. To set a character sets, select Characters in the Method field and navigate to the Characters field. In the dialog box that will open, you will be able to set new character sets, as well as edit and delete existing ones.Setting a character set
Select a character encoding standard
Select the appropriate character encoding standard from the drop-down lists in either the Code Page field or the Unicode Subrange field.
Review selected characters
The characters you select will be displayed in the Selected characters field. You can also specify a character set using a keyboard.
Regular Expression
Regular Expression describes the text being searched for using a regular expression. Regular expressions describe the structure of a word or any other entered value using a special language. A regular expression determines the possible character combinations and their positioning relative to each other, thereby describing the structure of the text being searched for. A regular expression search is precise - i.e. the formulated hypothesis should correspond precisely to the regular expression. Usually, this search method is used when document images are of high quality with no recognition errors. To describe the text being searched for using a regular expression, select Regular Expression in the Method field, and navigate to the field below. In the editor that will open, specify your regular expression.Regular expression alphabet
| Name in the list | Symbol in the field | Example |
|---|---|---|
| Any character | * | “k”*“t” – allows ‘kit’, ‘kat’, etc. |
| Letter | C | C”at” – allows cat, bat, Rat, mat, etc. |
| Upper case letter | A | A”at” – allows Cat, Bat, Rat, Mat, etc. |
| Lower case letter | a | a”at” – allows car, bat, rat, mat, etc. |
| Letter or digit | X | X – allows any single letter or digit. |
| Digit | N | N”th” allows 5th, 4th, 6th, etc. |
| String | "" | "cat” |
| Or | | | “dr”(“i”|“u”)“nk” – allows “drink” or “drunk”. |
| Character from the set | [] | [hm]“at” – allows ‘hat’ or ‘mat’. |
| Character not from the set | [^] | [^b]“at” – allows ‘cat’, ‘mat’, ‘rat’, but does not allow bat. |
| Any number of repeats (applies to the expression or sub-expression to the left) | {-} | [AB74]{-} – allows any combination of A, B, 7, 4 of any length. |
| Number of repeats is n | {n} | N{2}"th" allows 25th, 84th, 11th, etc. |
| n to m repeats | {n-m} | N{1-3}"th" allows 5th, 84th, 111th, etc. |
| 0 to n repeats | {-n} | N{-2}"th" allows th, 84th, 4th, etc. |
| n or more repeats | {n-} | N{2-}"th" allows 25th, 834th, 311th, 34576th, etc. |
| Subexpression | () |
Examples of regular expressions
| Use case | Regular expression | Sample values |
|---|---|---|
| Postal code | [0-9]{6} | ”142172” |
| Zip code (USA) | [0-9]{5}("-"[0-9]{4}){-1} | ”55416”, “33701-4313” |
| Income | N{4-8}[,]N{2} | ”15000,00”, “4499,00” |
| Month (numerical) | ((|"0")[1-9])|("10")|("11")|("12") | ”4”, “05”, “12” |
| Fraction | ("-"|)([0-9]{1-})(|(("."| ",")([0-9]{1-}))) | ”1234,567”, “0.99”, “100,0”, “-345.6788903” |
[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-3}"@"[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-4}"."([A-Za-z]{2-4}|"asia"|"museum"|"travel"|"example"|"localhost") | ”support@abbyy.com”, “my-name@company.org.ru”, “info@gallery.museum” |
Extended regular expressions
Extended regular expressions are regular expressions with additional functionality enclosed between an opening bracket followed by a percent character and a percent character followed by a closing bracket ([% and %]). Extended regular expressions have the following additional features:
- One or more characters inside the brackets are supplemented with popular OCR errors. For example,
[%S%]may allow S, $, and 5. - Special words inside
[%...%]for common character sets and OCR errors:- LETTERS — Capital Latin letters and characters commonly recognized as capital Latin letters.
- DIGITS — Digits and characters commonly recognized as digits.
- LETTERSANDDIGITS — Capital Latin letters, digits, and characters commonly recognized as capital Latin letters and digits.
[%DIGITS%]{9} specifies nine consecutive digits or common OCR errors for digits, e.g. “OI234Sb7B9”.
Additional properties
- Allowed errors specifies the maximum allowed recognition error percentage. In other words, it denotes the maximum allowed percentage of total characters that can be from outside the defined character set. The hypothesis for an object can only be formulated if the recognition error percentage for it is not higher than the specified value.
- Word count specifies the minimum and maximum number of words in the text being searched for.
- Character count specifies the minimum and maximum number of characters in the text being searched for.
- Search for parts of words specifies whether word fragments are allowed in hypotheses. Disable this option if you need to exclude hypotheses with word fragments and search only for entire words.
Advanced properties
- Allow embedded hypotheses allows using characters in the search area to generate all the possible hypotheses - including intersecting and embedded hypotheses.
- Max. space length allows specifying the maximum length of the space inside the detected object.
- Text orientation allows specifying the orientation of the text you’re looking for. By default, the activity only looks for text oriented horizontally and won’t formulate a hypothesis for rotated text. If you need to find the text rotated in a specific way and ignore the text written in any other direction, you should select only the Clockwise or the Counter-clockwise option. To find text regardless of its orientation, you should enable all available options.
- Detect words by specifies how lines should be divided into words: automatically (Pre-Recognition) or by dividing a line into words (Interword Space) whenever the space between neighboring characters is greater than or equal to the value entered in Min. interword space.