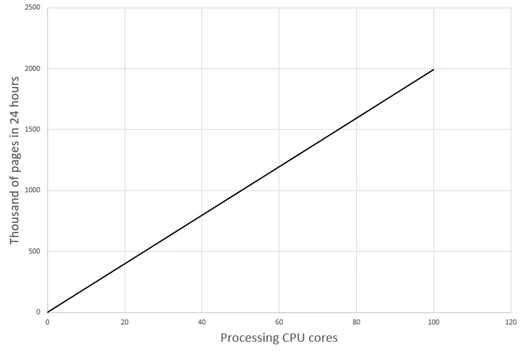
処理コア数に対するパフォーマンスの依存関係
処理コア数を見積もる
- プロジェクトのワークフローを設定し、本番環境の構成に最も近いハードウェアの Processing Station を選択して、典型的な画像バッチを作成します。
- 1つのコアで1つのバッチを処理するのにかかる時間を測定します。バッチを1回だけ処理しても十分ではありません。テスト中は FlexiCapture が利用可能なすべてのコアに処理を分散するため、バッチは、本番環境で他のコアが別のバッチの処理で使用中の場合よりも早く完了します。信頼できる値を得るには、典型的なバッチのコピーを複数作成してください。少なくともコア数と同じ数、理想的にはその N 倍 (N ≥ 3) です。そして、それらをすべて同時に処理します。1コアあたりの1バッチの処理時間は、総処理時間を N で割った値であり、これにはコア同士が ステーション の共有リソースを競合する影響も含まれます。
-
必要なコア数を計算します。
ここで、P は処理するページ数、t は1ページを処理する時間、T は利用可能な時間です。
計算例
- Hyper-Threading を備えた 8 コアの Processing Station では、16 個の論理コア (16 個の実行プロセス) が利用できます。
- 一般的なバッチのコピーを 16 × 3 = 48 個作成し (測定誤差を減らすために ×3) 、それらをすべて一度に処理します。
- 実行時間は 15 分 です。各コアで 3 つのバッチを処理するため、1 つのバッチの処理時間は約 5 分 です。
- このバッチは 69 ページ あるため、1 ページあたり約 4.35 秒 かかります。
- 8 時間で 200,000 ページを処理するには (28,800 秒) 、N = (200,000 × 4.35) / 28,800 ≈ 31 コア となります。
- したがって、自動処理には Hyper-Threading を備えた 8 コアの Processing Station 2 台 (合計 32 論理コア) で十分です。
制限要因
インフラストラクチャの負荷
- FlexiCaptureサーバーのハードウェア
- ネットワーク
- カスタム処理スクリプトからアクセスされる外部の共有リソース (データベースや外部サービスなど)
Processing Server capacity
- 可能であれば、バッチ 全体を小さな tasks に分割せずに処理します (Workflow settings ダイアログの Stage Properties を参照) 。
- より大きな単位でページを処理します。1 バッチあたりの平均ページ数を増やす、複数のカスタム ステージ を 1 つにまとめる、またはカスタマイズを標準 stage に移す方法があります。たとえば、その stage の script のルーティングイベントに追加できます。