A
ABBYY FlexiCapture
構造化文書 (fixed forms) 、半構造化文書 (flexible forms and documents) 、非構造化文書 (free-format documents) など、さまざまな文書タイプから単一のフローでデータを抽出するためのソフトウェアソリューション。ABBYY FlexiLayout Studio
文書構造の FlexiLayout を作成し、自動文書認識に利用できるプログラムです。ABBYY FormDesigner
ABBYY FormDesigner は、機械可読フォームのレイアウトを設計するためのツールです。これらのフォームは、印刷して記入した後、ABBYY FlexiCapture の自動フォーム入力システムで処理できます。フォームのレイアウト設計は重要な工程です。設計したレイアウトの品質 (機械可読性) が、その後のすべての処理工程、つまりスキャン、認識、検証、エクスポートの有効性を左右するためです。FlexiCapture for Invoices
ADF
管理者
アルファベット
アンカー
詳細...
詳細...
アンカーはフォーム設計における特別な要素で、システムがスキャン後にマッチングを実行するために使用されます (傾きを補正し、スキャン時の線形・非線形のゆがみを補正し、ブロックの位置を計算します) 。最も信頼性の高いアンカーは黒い四角形で、通常はフォームの四隅に配置されています。画像上に特別なアンカーがない場合は、他の静的要素を使って Document Definition のマッチングを行うこともできます。たとえば、区切り線、つまりテーブルの罫線や枠線などの縦線または横線、あるいは明確な静的テキスト (フォームのヘッダー、フィールドのラベル、説明情報など) です。Document Definition のマッチングに使用する静的要素では、Use for Document Definition matching オプションを有効にする必要があります。
アンカーバーコード
データ抽出を目的としないバーコードを表す静的要素です。アンカーバーコードは、Document Definition のマッチングや識別に使用できます。アンカーテキスト
空白フォーム上に存在し、データ抽出を目的としないテキストを表す静的要素です。説明文や見出しなどのテキストが該当します。アンカーテキストは、Document Definition のマッチングや識別に使用できます。角
角形の基準マーク。別紙
フィールドを含まないものの、ドキュメントのアセンブリに含まれるページです。これらのページからデータは抽出されませんが、画像または検索可能な PDF ファイルとして保存できます。(管理者) 別紙を含む文書の Document Definitions の作成を参照してください。アセンブリ エラー
自動学習
B
バーコード
一定の長さの白黒のバーが交互に並んだ、デジタル情報を符号化する機械可読なフォーム要素です。文書内のバーコードは、情報の抽出 (Barcode フィールド) や、Document Definition の照合と識別 (アンカーバーコード) に使用できます。Barcode フィールド
認識対象のバーコードを含む Document Definition の field。バーコード認識
バーコードの画像を数値またはテキストに変換すること。バッチタイプ
白黒罫線フォーム
黒い四角
明るさ
スキャナがグレースケールの中間調を白として検出する境界を決める、光感度のしきい値です。C
チェックマーク
記入者がチェック、バツ、点、塗りつぶしなどの印を付ける、機械可読なフォーム要素です。チェックマーク field
チェックマークグループ
近接して配置された複数のチェックマークを1つのまとまりとして扱う、機械可読な帳票の要素です。チェックマークグループでは、1つまたは複数のチェックマークを選択できます。チェックマークグループfield
チェックマークグループを含むDocument Definitionのfield。分類器
FlexiLayout Studio で作成されるプロジェクトで、Document Definitions を適用する前にページを事前に識別し、対応する FlexiLayout または代替レイアウトを選択するためのものです。分類器のF-measure
ドキュメント分類における適合率と再現率を組み合わせた指標です。0 から 1 までの数値、または 0% から 100% までの百分率で表されます。 カテゴリのF-measureは、(β^2 + 1) * P * R / (β^2 * P + R) で計算されます。ここで、P はそのカテゴリの適合率、R はそのカテゴリの再現率、β は対象のモデルにおける適合率と再現率の相対的な重み付けを決定する自由パラメータです。P = R = 1 (100%) のとき、最大値は 1 (100%) です。 テスト用または学習用バッチのF-measureは、(β^2 + 1) * P * R / (β^2 * P + R) で計算されます。ここで、P はそのテスト用または学習用バッチの適合率、R はそのテスト用または学習用バッチの再現率、β は対象のモデルにおける適合率と再現率の相対的な重み付けを決定する自由パラメータです。コードページ
色付き背景のフォーム
コントラスト
画像内の最も暗い部分と最も明るい部分の明るさの比率。コントロール
修正済みチェックマーク
十字
十字形のアンカー。カスタムデータ型
ユーザー定義のデータ型。 (管理者) カスタムデータ型の作成をご覧ください。D
データベースルックアップ
データセット
データ型
詳細...
詳細...
field の特性の 1 つに、データ型があります。データ型には、数値、日付、テキスト、姓、名、住所などがあります。データ型は、その field に現れる可能性のある単語の集合を定義します。データ型は、認識精度に影響する重要な認識パラメーターです。データ型を正しく指定すると、誤認識される文字数を大幅に減らすことができます。
説明ファイル
Hot Folder から画像を追加する際に、バッチの作成方法を定義する補助ファイルです。(管理者) 詳細については、説明ファイルを参照してください。辞書
詳細...
詳細...
辞書はデータ型の作成時に指定します。したがって、field にアタッチされたデータ型によって、認識時および検証時に使用される辞書が決まります。あらかじめ用意された辞書を持つ既存の定義済みデータ型に加えて、このプログラムでは、カスタム辞書に基づいて作成したデータ型もアタッチできます。辞書データは手動で入力することも、ファイルからロードすることもできます。
ドキュメント
文書バッチ
ユーザーがグループ化した文書の組み合わせです。通常、バッチには1回のスキャンで取り込まれた一連の文書、または特定のフォルダーからインポートされた文書が含まれます。(管理者) 文書バッチを参照してください。ドキュメントクラス
文書データ
文書ページ画像の処理 (認識、検証、認識結果の編集) 後に抽出されるデータ。Document Definition
Document Definition は、特定の種類の文書を識別して処理するための原則を定義するもので、次の内容が含まれます。- 文書構造。つまり、この種類の文書で許可されるページ順序の説明であり、文書をどのようにまとめるかを定義します
- 文書セクションの定義
- field データが満たすべきルールの一覧
- データ ウィンドウ (データ フォーム ビュー) 内の field とそのシグネチャの位置
- 文書のエクスポート設定
- 文書処理設定
Document Definition の識別
Document Definition のマッチング
Document Definition の公開
編集後の新しい Document Definition バージョンを利用可能にすること。公開済みバージョンは作業バッチ内のドキュメント処理に使用されますが、未公開のローカルバージョンはテストバッチの Document Definition の処理にのみ使用できます。(管理者) Document Definition の編集と公開を参照してください。Document Definition セクション
文書識別
文書セット
ドキュメントのテキスト
文書タイプ
文書バリアント
ドットマトリクスプリンター
認識可能なテキストの一種で、ドットマトリクスプリンターで印字されたテキストを表します。dpi
E
エンティティ
環境変数
エラー / 警告
エラー / 警告は、1 つ以上のfieldから抽出されたデータが、自動チェック時に適用されるルールを満たさない場合や、指定された形式に一致しない場合に発生します。エラー / 警告には、次の 2 種類があります。- 単一fieldのエラー / 警告 は、1 つのfieldに影響するルールや形式によって生成されます。
- 複数fieldのエラー / 警告 は、複数のfieldに影響するルールによって生成されます。
説明テキスト
フォーム名、field名、fieldの説明などの説明テキストを表す、機械可読なフォーム要素です。エクスポート
処理済みデータを外部の情報システムまたはファイルに転送する処理。エクスポートプロファイル
処理済みデータの扱いを決める設定一式です。出力ファイルの形式、出力先パス、エクスポート条件などを指定します。外部データベース
F
Field
データ抽出を目的としたドキュメントの要素です。field には、単純なもの (内部構造を持たないもの) と複合的なものがあり、たとえばテーブル field では、各セルをテーブルに属する個別の従属 field と見なすことができます。(Administrator) Document Definition field の作成を参照してください。field 領域
field検証
詳細...
詳細...
field検証モードでは、不確かな文字は field全体の文脈の中で確認されます。
Send to field verification オプションが有効になっている fieldは、field検証に送られます。値の範囲がわかっている、または容易に特定できる fieldを field検証に送ることをお勧めします。そのような fieldの例としては、国名や都市名があります。つまり、その fieldが取り得る値がわかっているということです。複数のインスタンスを持つ Field
複数の領域を持つ Field
領域のない field
Document Definition で検出されたものの、画像上に領域を持たない field。(管理者) 領域のない fieldを参照してください。固定フォーム
書式、数、レイアウトが厳密に定義されており、文書ごとに変わらない固定情報のfieldを持つ文書。Fixed Document Definition
fixed forms を処理するために設計された、ドキュメントまたはそのセクションの定義です。fixed Document Definition の field は、位置が固定されています。FlexiLayout
半構造化ドキュメントの構造を記述したものです。この記述は ABBYY FlexiLayout Studio で作成し、ABBYY FlexiCapture にエクスポートします。ファイル形式は *.afl です。FlexiLayout は、柔軟なフォーム内の field を検出して識別するための一種の定義です。FlexiLayout バリアント
Flexible Document Definition
半構造化文書の処理用に設計された、文書またはそのセクションの定義です。FlexiLayoutをアタッチして作成します。このような Document Definition の fieldには固定位置がありません。これらの fieldは FlexiLayout を使用して検出されます。(管理者) 半構造化文書処理用の Document Definition の作成を参照してください。帳票
手書きまたはその他の印字方法で人が記入するために作成された、1ページまたは複数ページで構成される文書。枠付きテキスト
枠で囲まれたテキストを示すテキストマーキングの種類です。表示...
表示...
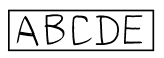
櫛形枠の上にある枠付きテキスト
表示...
表示...
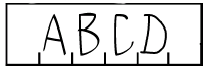
G
灰色の背景のフォーム
グループ検証
詳細...
詳細...
[グループ検証に送信] オプションが有効になっているfieldは、グループ検証に送信されます。数値field内の文字とチェックマークも、グループ検証に送信することをお勧めします。
H
手書きの活字体文字
判読可能なテキストの一種で、活字体で一文字ずつ手書きされた文字を指します。手書き文字
文字がつながっている、または一部がつながっている、認識可能なテキストの一種です。 注: 現在、認識できる手書き文字は英語のみです。Hot Folder
ローカルまたはリモートのコンピューターのハードドライブ上にあるフォルダーで、画像のインポートに使用されます。通常、ユーザーの操作なしで定期的に繰り返し行われる画像のアップロードに使用されます。(管理者) 画像インポートプロファイルを参照してください。I
識別子
アンカーの位置が同じ複数のDocument Definitionsの中から、特定のDocument Definitionを識別して選択するために使用する静的要素です。このような静的要素のプロパティでは、[Document Definition の識別に使用]オプションを有効にする必要があります。ID プロバイダー
Azure AD、OneLogin、Okta などのサードパーティ システムで、ID 情報を管理し、クライアントに認証サービスを提供するものです。これにより、エンド ユーザーは資格情報を一度入力するだけで、ローカル エリア ネットワーク内のアクセスを許可されたすべてのリソースにアクセスできます。無視される文字
詳細...
詳細...
これらの文字は単語から除外されます。つまり、単語はこれらの文字を含まないものとして、特定のデータ型に関連付けられます。
Image
紙の文書のページをスキャンして得られる電子画像。画像のノイズ除去
画像内のノイズを除去します。ノイズはスキャン時に発生することがあるため、データ認識の精度を高めるには除去することをお勧めします。ノイズ除去の際には、プログラムはラスター形式のフォームの背景のドットや枠線も削除します。画像のインポート
処理のために画像をバッチに追加する処理です。インポートは、ファイルやスキャナから画像を追加するか、インポートプロファイルを使用して実行できます。(管理者、検証) ページ画像の追加を参照してください。画像の回転
画像の中心を軸とした回転です。インポートプロファイル
画像をバッチに追加する際に使用する設定の組み合わせです。インポート元、画像処理オプション、Hot Folder のクリーンアップ オプションなどが含まれます。(管理者) 画像インポート プロファイルを参照してください。誤認識された文字
認識の確実性が著しく低い場合に、認識処理中の文字に自動的に割り当てられるステータスです。インデックスfield
文書の並べ替えや検索のためのインデックスとして使用される値を持つfieldです。 (管理者) インデックスフィールドを参照してください。反転画像
請求書
ICR、Intelligent Character Recognition
K
主要field
ページをドキュメントへ自動的にアセンブリする際のチェックに使用されるfieldです。主要fieldの値は、同じドキュメント内のすべてのページで一致している必要があります。L
言語 (ローカル)
文書の記載言語と、それに対応する地域パラメーターのセット (日付や住所の表記形式など) を決定するfieldプロパティ。Layout
枠で囲まれた文字
表示...
表示...

個別の枠内の文字
表示...
表示...

櫛形罫線に重なった文字
表示...
表示...
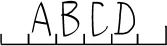
M
機械印字されたテキスト
活字組版機器、レーザープリンター、またはインクジェットプリンターで、解像度 300 dpi 以上で印刷された認識可能なテキストの一種です。機械可読フォーム
手動入力field
認識できないテキスト (たとえば、文字が癒着したテキスト) を含み、キーボードから入力する必要がある Document Definition のfield。MRC (Mixed Raster Content)
テキストとラスター片の両方を含む画像に使用される圧縮方式です。画像を断片ごとに解析し、それぞれに最適な圧縮アルゴリズムを選択します。この方式では、画像の見た目の品質を維持しながら、より高い圧縮率を実現できます。等幅テキスト
各文字が同じ高さ・幅の枠内に収まっているタイプのマーキングで、スキャン時には枠線が消えます。複数ページの文書
複数のページから成る文書。マルチテナンシー
N
NER (固有表現認識) 非構造化テキスト内の属性を検索し、それらを事前定義されたカテゴリに分類する情報抽出ジョブです。 NLP (自然言語処理) 人工知能および数理言語学の一分野です。自然言語のコンピューターによる解析と生成を扱います。応用例の 1 つとして、テキストから意味のある情報を抽出することが挙げられます。これには、機械翻訳、チャットボット、分類、感情分析、データ抽出などが含まれます。NLP モデル
O
OCR (光学文字認識)
OMR (光学式マーク認識)
オペレーター
オペレーター ロール
オーバーレイ
P
ページ
紙の文書ページの画像とその処理結果。ページレイアウト
画像上のfieldの位置を示す図。ページの向き
標準的な向き (上から下、左から右) に対するページの向きです。ページの向きは、ページ画像の認識時に自動的に判定できます。そのため、ABBYY FlexiCapture では想定される向きを指定できます。画像
認識の対象ではなく、グラフィックオブジェクト (ファイルなど) としてエクスポートすることを目的とした、機械可読フォームの要素です。画像field
画像を含む Document Definition のfieldです。 適合率 ユーザーが自動分類の精度を評価するための指標です。クラス A と判定されたすべての文書数 (正しく判定されたものと誤って判定されたものの両方) に対する、正しくクラス A と判定された文書数の割合として計算されます。事前認識
処理能力
(Distributed) 処理ステージ
禁止文字
詳細...
詳細...
このような文字を指定すると、認識速度と認識品質が大幅に向上することがあります。たとえば、大文字のみのテキストを認識する場合は、すべての小文字を禁止文字として指定します。
プロジェクト
プロジェクトとは、ドキュメントのバッチや、それらを処理するために必要な Document Definitions、インポートプロファイルなどの設定をまとめた環境です。 (Administrator) プロジェクトの作成を参照してください。(Distributed) Q
(Distributed) キュー
R
ラスターフォーム
ラスター線
等間隔のドットで構成される線。 再現率 ユーザーが自動分類の精度を評価するための指標です。正しく識別されたクラス A の文書数を、クラス A に属する全文書数で割って算出されます。認識
画像要素を特定の文字と照合する処理です。認識言語
Reference layout
自動的に作成されるレイアウトの参照として使用される、ユーザー作成のレイアウトです。この比較は、プログラムがfield regionをどの程度正確に検出できているかを評価するために行われます。(管理者) 正規表現
(管理者) 特殊な言語を使って、単語や入力された任意の値の構造を記述するものです。プログラムでは、使用可能な文字の集合だけでなく、field の内容の構造も指定できます。テキスト field の制約を設定する場合や、カスタムデータ型を作成する場合は、正規表現を使って構造を記述できます。正規表現で使用されるアルファベットを参照してください。解像度
Image パラメーター。解像度は 1 インチあたりのドット数 (dpi) で表されます。 結果クラス 結果クラスとは、自動分類時にドキュメントに割り当てられたクラスです。ルールの検証
認識されたデータを事前設定されたルールに照らして自動的にチェックすることです。詳しくは、ルールの検証を参照してください。ルール
field のデータに対して設定され、プログラムによって自動的にチェックされる特定の条件。(Administrator, Verification) ルールの検証を参照。S
スキャン
スキャナを使用して、紙のフォームを電子画像として取り込むプロセス。 セグメント 抽出が必要なデータを含む、1つ以上の段落で構成されるテキストフラグメント。セグメントは、抽出が必要なfieldである場合もあります (たとえば、契約終了の条件) 。 セグメンテーション セグメントを特定するプロセス。セグメンテーションは情報抽出に先立って行われ、特に大きな文書では、エンティティの検索対象を特定のテキストフラグメントに絞り込めるため有用です。セクション
文書内で論理的に区別される部分で、抽出可能な field のセットを含みます。セクションは、ページをまとめて文書を構成するなど、認識プロセス中のさまざまな目的で使用されます。セクションには 1 ページのみを含めることも、複数ページを含めることもでき、fixed または flexible にできます。(管理者) 複数ページ文書用の Document Definitions の作成を参照してください。半構造化文書
文書ごとに、情報フィールドの構成、数、レイアウトが大きく異なる場合がある文書。ABBYY FlexiCapture で処理できる文書の種類を参照してください。区切り線
縦線または横線を表す機械可読なフォーム要素です。サービス field
使用可能な文字セット
詳細...
詳細...
このセットはデータ型によって決まります。つまり、field にアタッチされたデータの型によって、認識時に使用される文字セットが決まります。このセットに含める文字を選択するだけでなく、このセットをさらに制限する追加のパラメーターを設定することもできます。たとえば、次のように指定できます。
- 特定の field の認識時に出現しないことが分かっている文字 (禁止文字) 。たとえば、大文字しか出現しない field では、すべての小文字を禁止文字として指定できます。
- 検証に影響を与えずに単語内に出現する可能性がある文字 (無視文字) 。たとえば、ハイフン、アクセント記号などです。
シンプルテキスト
区切り記号を使わずにブロック内へテキストを挿入する、テキストマーキングの一種です。単一フローでのデータ入力
紙文書 (印刷物) およびデジタル文書 (スキャン画像) からの自動データ抽出。単一フローでの文書入力
紙文書を電子化する自動変換。SLA (サービスレベル契約)
Static elements
Document Definition のマッチングと識別に使用される、認識対象ではない要素です。こうした要素には、アンカー、アンカーテキスト、区切り線、アンカーバーコードがあります。サマリーセクション
T
テーブル
テーブル field
(Distributed) タスク
テナント
テストバッチ
Document Definition のテストと設定用に設計されたドキュメントバッチです。テストバッチの処理には、ドキュメントバッチのローカルコピーが使用されます。(管理者) ドキュメントバッチを参照してください。Text field
Text field のマーキング
テキストマーキング
テキスト入力用のページ領域のデザイン。(管理者) テキストの書式設定のサンプルについては、Entry field トピックを参照してください。テキストの向き
ページに対するfield内のテキストの向き。テキスト認識 (OCR、ICR)
画像をテキストに変換すること。テキストサンプル
学習 [Document Definition]
学習用バッチ
Typewriter
タイプライターで印字された文字を表す、認識可能なテキストの種類です。U
下線付きのテキスト
表示...
表示...
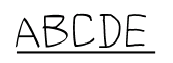
ユーザー辞書
ユーザーが作成する補助辞書で、組み込み辞書には含まれていない単語を収録します。組み込み辞書は、ユーザー辞書で補完することで、データ抽出の品質を向上させることができます。通常、ユーザー辞書には、専門用語、略語、会社名などが含まれます。認識対象外の領域
認識から除外された画像領域です。認識対象外の領域は、field の認識を難しくする説明文や画像を含む領域を除外するために必要です。 (管理者) 認識から領域を除外するを参照してください。非構造化文書
自由形式で情報が記載された文書です。このような文書の例として、契約書、手紙、注文書、グラフなどがあります。(管理者) 非構造化文書および半構造化文書の Document Definition の作成を参照してください。V
ベンダー
検証
検証では、データが認識されていること、ページがドキュメントとして正しくまとめられていること、およびルールでエラーが返されていないことを確認します。 (Standalone) 検証は Operator Station で行われます。 (Distributed) 検証は Data Verification Station (認識精度を検証する場所) および Verification Station (あらゆる種類の確認を実行できる場所) で行われます。 (Administrator, Verification) 検証を参照してください。W
作業バッチ
データ入力用のドキュメントバッチです。作業バッチの処理には、公開済みの Document Definitions のみが使用されます。(管理者) ドキュメントバッチを参照してください。筆記スタイル
詳細...
詳細...
このオプションでは、帳票内の手書き風文字の筆記スタイルを設定します。選択する筆記スタイルは、帳票処理を行う地域 (ロシア、ドイツ、チェコ共和国、USA など) によって異なります。