名前付きエンティティの最後の出現箇所を見つける
直近の組織インスタンスを抽出するためのルール
例
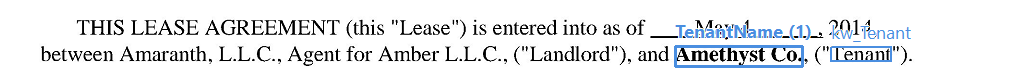
金額が文字表記と数字表記の両方で記載されている場合の抽出
合計金額を抽出するためのルール
例

キーワードによるセグメントの検索
第2レベル見出しを kw_Heading2 検索要素に抽出するためのルール
セグメントを「Segment search」要素に抽出するためのルール
例

kw_Heading2 検索要素に抽出され、その後、連続する2つの kw_Heading2 検索要素の間にあるテキストが、Segment 検索要素のインスタンスとして抽出されます。
各エンティティに関する情報のグループ化
- 組織名を検出し、見つかった各名称に対して
Party_Groupのグループ検索要素の新しいインスタンスを作成し、その子検索要素「Organization_Name」に値を設定します。 - 各組織名のインスタンスから、例えば20トークン以内の範囲にある住所と役割を探し、その組織名の親である
Party_Groupのインスタンスにアクセスして、そのインスタンス内の子検索要素「Address」および「Role」に値を設定します。
Organization_Name 検索要素の抽出ルール
Address 検索要素の抽出ルール
役割検索要素抽出のルール
例


日付と時刻をまとめて検出する
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?)。次に、その近傍にある Date という名前のエンティティを探します。最後に、検出したトークン列を連結し、結果を「TimeAndDate」という名前の検索要素に割り当てます。
日付と時刻の併記抽出ルール
例
