Methode
Zeichen
Festlegen eines Zeichensatzes
1
Zeichenkodierungsstandard auswählen
Wählen Sie den passenden Zeichenkodierungsstandard aus den Dropdown-Listen im Feld Code Page oder im Feld Unicode Subrange.
2
Zeichen auswählen
Wählen Sie die entsprechenden Zeichen in der untenstehenden Tabelle aus.
3
Ausgewählte Zeichen überprüfen
Die ausgewählten Zeichen werden im Feld Selected characters angezeigt. Sie können einen Zeichensatz auch über die Tastatur festlegen.
4
Anteil der Zeichen angeben
Geben Sie im Feld
Portion in text, % den Anteil der Zeichen (von 0 bis 100) an, die im gesuchten Text enthalten sind.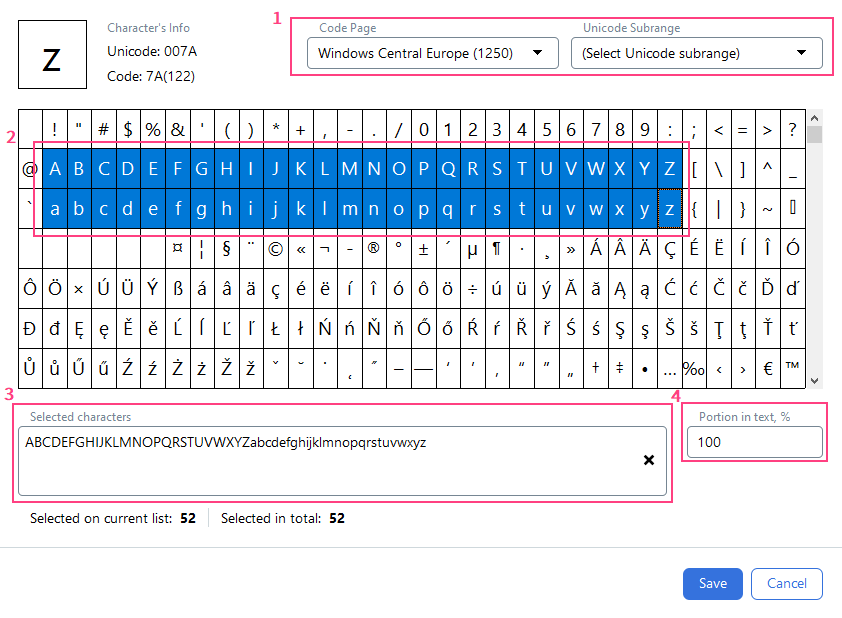
Regulärer Ausdruck
Alphabet der regulären Ausdrücke
Beispiele für reguläre Ausdrücke
Erweiterte reguläre Ausdrücke
[% und %]). Erweiterte reguläre Ausdrücke bieten die folgenden zusätzlichen Funktionen:
- Ein oder mehrere Zeichen innerhalb der Klammern werden um typische OCR-Fehler erweitert. Zum Beispiel kann
[%S%]S, $ und 5 zulassen. - Spezielle Schlüsselwörter innerhalb von
[%...%]für gängige Zeichensätze und OCR-Fehler:- LETTERS — Großbuchstaben des lateinischen Alphabets sowie Zeichen, die häufig als solche erkannt werden.
- DIGITS — Ziffern sowie Zeichen, die häufig als Ziffern erkannt werden.
- LETTERSANDDIGITS — Großbuchstaben des lateinischen Alphabets, Ziffern sowie Zeichen, die häufig als Großbuchstaben bzw. Ziffern erkannt werden.
[%DIGITS%]{9} neun aufeinanderfolgende Ziffern oder typische OCR-Fehler für Ziffern an, z. B. “OI234Sb7B9”.
Zusätzliche Eigenschaften
- Zulässige Fehler gibt den maximal zulässigen Erkennungsfehlerprozentsatz an. Anders ausgedrückt bezeichnet er den maximal zulässigen Anteil der Gesamtzeichen, die außerhalb des definierten Zeichensatzes liegen dürfen. Eine Hypothese für ein Objekt kann nur gebildet werden, wenn der Erkennungsfehlerprozentsatz den angegebenen Wert nicht überschreitet.
- Wortanzahl gibt die minimale und maximale Anzahl an Wörtern im gesuchten Text an.
- Zeichenanzahl gibt die minimale und maximale Anzahl an Zeichen im gesuchten Text an.
- Nach Wortteilen suchen legt fest, ob Wortfragmente in Hypothesen zulässig sind. Deaktivieren Sie diese Option, wenn Sie Hypothesen mit Wortfragmenten ausschließen und nur nach vollständigen Wörtern suchen möchten.
Erweiterte Eigenschaften
- Eingebettete Hypothesen zulassen ermöglicht die Verwendung von Zeichen im Suchbereich, um alle möglichen Hypothesen zu generieren – einschließlich sich überschneidender und eingebetteter Hypothesen.
- Max. Leerzeichenlänge ermöglicht die Angabe der maximalen Länge des Leerraums innerhalb des erkannten Objekts.
- Textausrichtung ermöglicht die Angabe der Ausrichtung des gesuchten Textes. Standardmäßig sucht die Aktivität nur nach horizontal ausgerichtetem Text und formuliert keine Hypothesen für gedrehten Text. Wenn Sie Text finden müssen, der in einer bestimmten Weise gedreht ist und Text in allen anderen Richtungen ignorieren möchten, sollten Sie nur die Option Im Uhrzeigersinn oder Gegen den Uhrzeigersinn auswählen. Um Text unabhängig von seiner Ausrichtung zu finden, sollten Sie alle verfügbaren Optionen aktivieren.
- Wörter erkennen anhand legt fest, wie Zeilen in Wörter unterteilt werden: automatisch (Vor-Erkennung) oder durch Aufteilen einer Zeile in Wörter (Zwischenwortabstand), wenn der Abstand zwischen benachbarten Zeichen größer oder gleich dem in Min. Zwischenwortabstand eingegebenen Wert ist.