Si todas las hipótesis de la cadena de elementos del elemento de grupo tienen un valor de calidad de 1, no se analizarán las demás hipótesis de estos elementos.
Esto se hace para optimizar el FlexiLayout, acelerar el procedimiento de emparejamiento y evitar la “ramificación” no deseada del árbol de hipótesis. Sin embargo, una hipótesis que es óptima para FlexiLayout Studio no necesariamente corresponde al objeto buscado en la imagen.Esto puede ocurrir si las restricciones de búsqueda del elemento no son lo bastante estrictas. Cuando se produce una situación así, analice primero los parámetros establecidos para la búsqueda del elemento.
El proyecto de ejemplo GO.fsp
GO.fsp (carpeta %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\GO\1), cuyo objetivo es encontrar el campo “Número de factura”.
El proyecto tiene dos páginas:
- Página 1 – La calidad de la imagen es buena.
- Página 2 – El nombre del campo buscado presenta ruido.
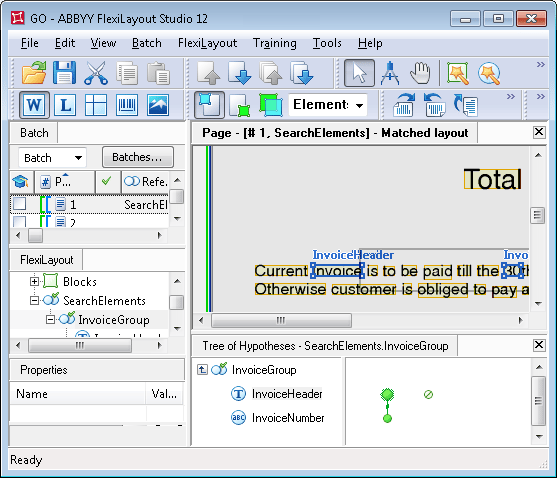
El proyecto contiene el grupo InvoiceGroup, que contiene el elemento utilizado para buscar el nombre del campo: un elemento de texto estático llamado InvoiceHeader con el valor “INVOICE”.
Para buscar el propio campo “Número de factura”, el proyecto utiliza un elemento de cadena de caracteres llamado InvoiceNumber. Las restricciones de búsqueda del campo con respecto al nombre se especifican en la sección Relations del elemento InvoiceNumber.
No importan las mayúsculas y minúsculas del nombre en la sección Texto a buscar.
Por qué la generación de hipótesis se detiene en una cadena de calidad 1
Para ver el árbol de hipótesis del grupo, haga doble clic en el nombre del elemento grupo en el árbol de hipótesis, pulse Enter o seleccione Mostrar detalles en el menú contextual.
Ancle el nombre al borde derecho de la página con Nearest
Nearest: PageRight;.
Esto funciona porque el nombre del campo buscado “Número de factura” es el único elemento más próximo al borde derecho de la página. Si no fuera así, o si el documento no tuviera un formato estandarizado, la función Nearest no podría resolver el problema.
Penalización de hipótesis numéricas distantes con FuzzyQuality
{0, 0, 0, 10000}*dt.
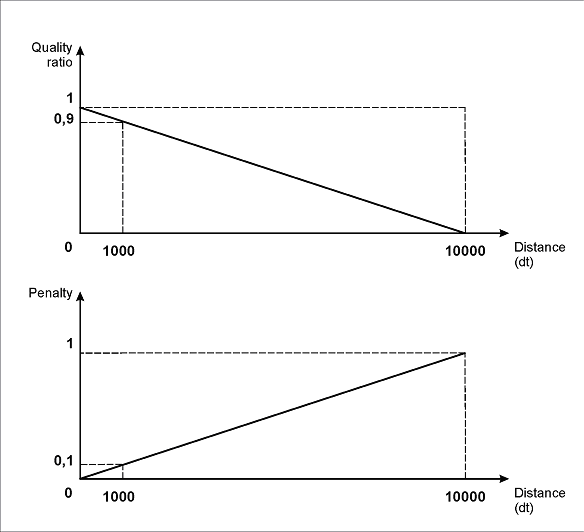
Esta descripción del intervalo muestra la dependencia lineal entre la calidad de la hipótesis y la distancia entre los elementos: cuanto mayor sea la distancia, mayor será la penalización (la función FuzzyQuality devuelve la calidad de posbúsqueda de la hipótesis, que puede verse en la ventana Propiedades de la hipótesis).
El valor del límite derecho del intervalo (10000dt) se determinó experimentalmente. Al elegir este valor, debe tener en cuenta la distancia entre los objetos correspondientes en las imágenes de prueba.
Como muestra la figura siguiente, con las propiedades del intervalo especificadas, la penalización máxima (1) corresponderá a una distancia de 10000dt. En consecuencia, una distancia de 1000dt dará una penalización de 0,1; una distancia de 100dt, una penalización de 0,01; etc.
Así, para distancias reales de aproximadamente 100-300 puntos, que pueden verse en las imágenes, el coeficiente de penalización será de 0,99 a 0,97.
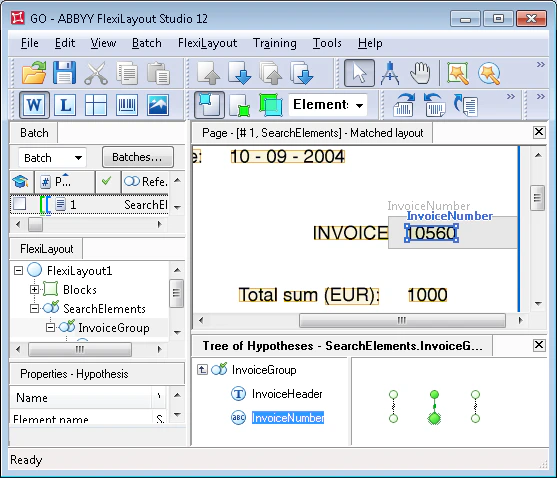
Para las imágenes de este lote, la hipótesis correspondiente al campo no deseado “Número de factura” con el valor “2005” recibió la penalización máxima, mientras que la hipótesis correspondiente al campo buscado recibió la penalización mínima.
Dado que la penalización hizo que la calidad de posbúsqueda de todas las hipótesis fuera distinta de 1, ahora se analizarán todas las hipótesis de ambos elementos del elemento grupo InvoiceGroup.
Tenga en cuenta que el campo “Número de factura” se detectó correctamente incluso en la página 2, donde el nombre “Invoice” tiene mucho ruido, lo que provocó un error de reconocimiento y, en consecuencia, penalizaciones adicionales para la hipótesis.