8 puede reconocerse como B, 7 como ?, 5 como S y 4 como H o como la combinación de letras LI. Esto puede ocurrir si los dígitos están “pegados”, algo habitual cuando los documentos se rellenan con una máquina de escribir.
Agregue caracteres reconocidos erróneamente al alfabeto
Desde luego, no es necesario especificar* todas*las posibles variantes de reconocimiento. Si la calidad de las imágenes es mala, encontrar todas esas variantes puede ser una tarea extremadamente laboriosa.Si, debido a la baja calidad de la imagen, los resultados del reconocimiento son impredecibles, debe ejecutar la búsqueda utilizando otras propiedades del elemento, como la longitud de la cadena y la longitud de los espacios en la cadena.
Emparejamiento con un alfabeto compuesto solo por dígitos
1.fsp (carpeta Digital strings\Project1).
El proyecto tiene tres páginas, cada una con un error de reconocimiento diferente:
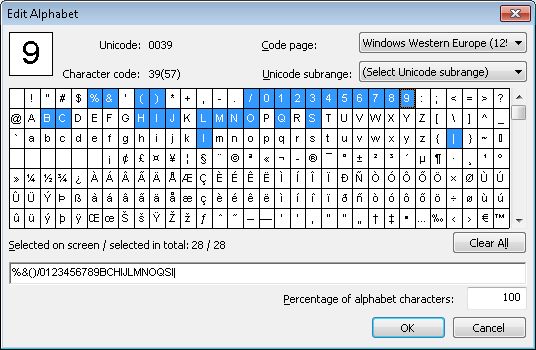
Para detectar la cadena de dígitos, el proyecto usa un elemento cadena de caracteres llamado DigitalString, con solo dígitos especificados en su alfabeto. El porcentaje máximo de caracteres no numéricos se ha establecido en un 20 %.
Después de ejecutar el procedimiento de emparejamiento de FlexiLayout en todas las páginas, el campo de dígitos de la página 3 no se detectó por completo. El valor de calidad de la hipótesis es de aproximadamente 0.98. En las páginas 1 y 2, se detectó la cadena. Sin embargo, como contiene caracteres ajenos al alfabeto, las hipótesis correspondientes fueron penalizadas y su calidad es de 0.978 y 0.982, respectivamente.
Nuevo emparejamiento con el alfabeto ampliado
L, I, e, a, B, S).
El resultado del emparejamiento de FlexiLayout puede verse en el proyecto 2.fsp (carpeta %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Digital strings\Project2).
Los demás ajustes de los proyectos son idénticos.
Como puede ver, la cadena de la página 3 se ha detectado por completo y la calidad de todas las hipótesis generadas es 1.