Para simplificar, en este ejemplo se utiliza un documento de una sola página.
FuzzyQuality, así como de las funciones del grupo Nearest (Nearest, NearestX, NearestY).
En qué se diferencian las funciones Nearest y FuzzyQuality
Nearest solo puede utilizarse en el campo relación avanzada de prebúsqueda. Especifica que, entre las distintas hipótesis del elemento, FlexiLayout Studio debe seleccionar la hipótesis más cercana a un determinado elemento o punto de la imagen, definido en las propiedades de la función Nearest.
En el campo relación avanzada de prebúsqueda del elemento, solo puede utilizarse una función del grupo Nearest. Después de ejecutarla, solo queda una hipótesis. Esto ocurre en la etapa de generación de hipótesis, es decir, antes de que se ejecute el código especificado en el campo Relaciones avanzadas de posbúsqueda.
El parámetro Minimum quality, que especifica la calidad mínima de las hipótesis del elemento, puede definirse para los elementos texto estático, cadena de caracteres, párrafo, fecha y separador.
No hay garantía de que la hipótesis restante sea la mejor (ni de que corresponda al objeto requerido de la imagen), porque las Relaciones avanzadas de posbúsqueda son muy importantes para asignar un valor de calidad a una hipótesis. Al utilizar la función Nearest, la elección de la hipótesis se realiza en la etapa de generación de hipótesis y se basa en la proximidad a algún punto, no en la calidad de la hipótesis.
Siempre debe tenerse en cuenta que, si las propiedades especificadas en la sección Relaciones avanzadas de posbúsqueda son importantes para seleccionar correctamente la hipótesis, debe utilizarse la función FuzzyQuality en lugar de las funciones del grupo Nearest.
La función FuzzyQuality solo puede utilizarse en la sección Relaciones avanzadas de posbúsqueda. A diferencia de las funciones del grupo Nearest, no selecciona una única hipótesis, sino que influye en la calidad general de todas las hipótesis generadas en función de las propiedades de dichas hipótesis y de los parámetros de la función FuzzyQuality.
Además, la función FuzzyQuality puede utilizarse varias veces para un mismo elemento en el campo Relaciones avanzadas de posbúsqueda. Esto significa que a una hipótesis pueden aplicársele varias restricciones distintas con diferentes valores de calidad. Todos los valores se multiplicarán para determinar la Post-search quality de la hipótesis.
La función FuzzyQuality tiene el siguiente aspecto:
El proyecto de ejemplo FuzzyAndNearest
Nearest y FuzzyQuality en las siguientes imágenes.
 |  |
|---|---|
 |  |
1.fsp (carpeta %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\FuzzyAndNearest \Project1).
Para optimizar la estructura de FlexiLayout y seguir la lógica de la disposición de los campos buscados en el documento, el proyecto agrupa todos los elementos buscados en un elemento compuesto, InvoiceGroup.
La creación de FlexiLayout podría comenzar con un elemento que describa las restricciones de búsqueda para el nombre del campo “Número de factura”. Sin embargo, un análisis de las imágenes muestra que la palabra “Invoice”, que forma parte del nombre, aparece varias veces en el documento.
Como la ubicación relativa de los campos cambia en cada caso, es imposible especificar restricciones que garanticen la detección correcta de la palabra “Invoice”. Por ejemplo, puede encontrarse en el nombre “Invoice date”.
Para evitar esta confusión, la descripción comienza con el nombre del campo de fecha, mediante un elemento de texto estático llamado DateHeader. El campo Texto a buscar especifica dos variantes del nombre: Invoicedate:|Invoicedate (enumerando las variantes del nombre tal como aparecen en las imágenes). El uso de mayúsculas y minúsculas en el nombre es irrelevante.
Para obtener más información sobre por qué debe especificar ambas variantes, consulte Establecer varios valores de texto estático para variantes de nombres de campo.
Buscar el campo de fecha con un array de rectángulos
Para obtener una descripción detallada de cómo crear un FlexiLayout para la búsqueda de fechas, consulte Date search after high or low-quality recognition.
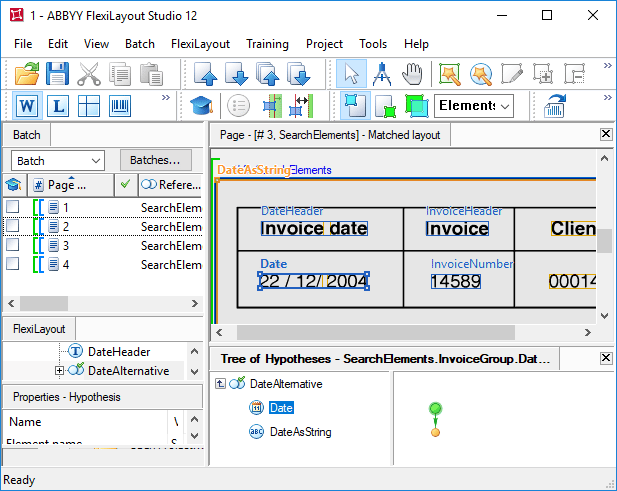
La primera línea del código (
let Header = InvoiceGroup.DateHeader;) lo simplifica al definir la variable Header y asignarle el valor del elemento DateHeader.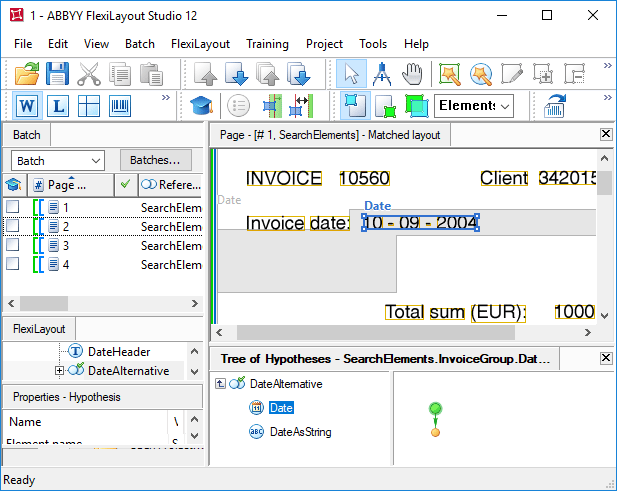
Para especificar el área de búsqueda del elemento DateAsString como un array de rectángulos, en lugar de llamar a
RestrictSearchArea (Date.Rect), copie el código correspondiente de la sección relación avanzada de prebúsqueda del elemento fecha.Detectar el nombre del campo Invoice con Exclude y NearestY
Para obtener más información sobre la búsqueda óptima de elementos en el grupo, consulte Optimización de la búsqueda de elementos de grupo.
Si FlexiLayout se hubiera iniciado no con el nombre DateHeader, sino con el nombre InvoiceHeader, no se podría haber usado la función
Exclude, ya que esta función solo puede excluir elementos ubicados por encima del elemento actual en el árbol del proyecto.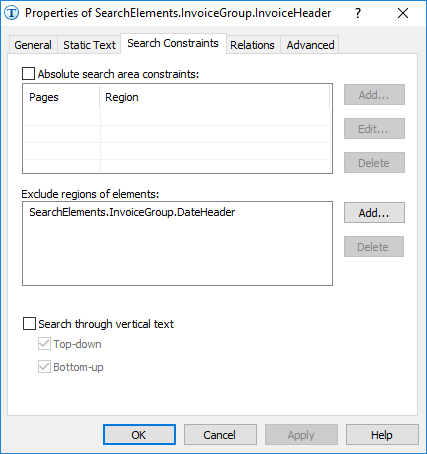
Nearest se cumple para ambas cadenas “Invoice”, porque están ubicadas al mismo nivel. Como la calidad de reconocimiento de las cadenas “Invoice” es buena en ambos casos, el algoritmo de optimización generó una sola hipótesis en lugar de dos independientes. Desafortunadamente, esta hipótesis no es correcta.
Buscar el número de factura con Nearest
Como alternativa (para las imágenes del proyecto actual) a
Nearest: Header;, podría escribir NearestY: Header.Rect.YCenter; para indicar a FlexiLayout Studio que el campo buscado es el más cercano, en sentido vertical, al centro del nombre.Esto podría resolver el problema de la detección incorrecta del campo “Número de factura” en la página 4. Sin embargo, no ayuda en la página 5, porque el campo buscado se detecta dentro del campo de fecha después de detectar incorrectamente el nombre “Número de factura”.Sustituya Nearest por penalizaciones de FuzzyQuality
FuzzyQuality en una situación como esta.
Esto se muestra en el proyecto 2.fsp (carpeta FuzzyAndNearest\Project2).
La configuración de este proyecto es casi idéntica a la del proyecto descrito anteriormente.
Sin embargo, hay una diferencia importante: la función Nearest no se usa en la sección de relación avanzada de prebúsqueda. En su lugar, la sección Relaciones avanzadas de posbúsqueda contiene el siguiente código:
FuzzyQuality: Rect.Top - PageRect.Top, {0,0,0,50000} * dt; significa que, si se genera una hipótesis no nula (primero se ejecuta la comprobación if not IsNull), se determina la distancia entre la posición del elemento y el borde superior de la página. Es decir, se calcula la diferencia (Rect.Top - PageRect.Top) y FlexiLayout Studio comprueba si esta diferencia pertenece al intervalo {0, 0, 0, 50000}*dt.
Esta descripción del intervalo significa que la penalización de calidad depende directamente de la distancia entre el elemento y el borde superior de la página: cuanto mayor sea la distancia, mayor será la penalización.
Como se muestra en la imagen (a), con los valores de parámetro especificados, la penalización máxima (1) corresponde a una distancia de 50000dt, mientras que una distancia de 1000 puntos (1 punto es 1/300 de pulgada) implica una penalización de 0.02, y una distancia de 100dt implica una penalización de 0.002.
Al elegir los parámetros que establecen los límites del intervalo (en particular, cuando hay varias comprobaciones de elementos con la función
FuzzyQuality), asegúrese de que no penalicen tanto la hipótesis correcta como para que su calidad final sea inferior a la de una hipótesis nula.Si la calidad de todas las hipótesis (incluida la correcta) es inferior al valor de calidad de una hipótesis nula, puede seleccionarse la hipótesis nula; es decir, el elemento no se detectará.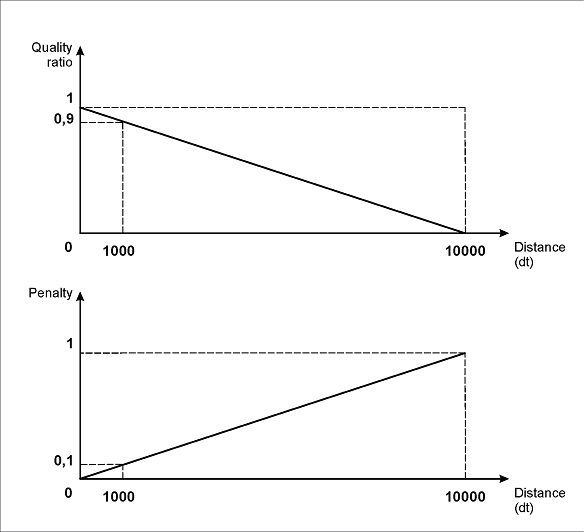
(a)
FuzzyQuality: 500dt - Width, {0,0,0,100000}*dt; significa que FlexiLayout Studio considera la diferencia entre 500dt y la anchura del objeto detectado correspondiente a la hipótesis. Es decir, se calcula la diferencia (500dt - Width) y FlexiLayout Studio comprueba si esta diferencia pertenece al intervalo {0, 0, 0, 100000}*dt.
Cuanto más estrecho sea el objeto, mayor será la penalización, por lo que se dará preferencia a los números de factura más largos. Esta restricción puede utilizarse si la imagen tiene ruido. Si el ruido se reconoce como un carácter del alfabeto especificado (como puede verse, por ejemplo, en la página 2), su hipótesis debe penalizarse para excluirla del análisis posterior.
El valor de 500dt se elige mediante inspección visual, suponiendo que la longitud de la cadena en el campo “Número de factura” no sea mayor que este valor. Los parámetros especificados aquí definen que la penalización máxima (0.005) correspondería a una anchura cero del campo “Número de factura”. Para cualquier otra anchura entre 0 y 500dt, las penalizaciones de calidad serían menores.
FuzzyQuality: Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt; significa que, si se genera una hipótesis no nula del elemento correspondiente al nombre del campo “Número de factura” (primero se ejecuta la comprobación if not InvoiceHeader.IsNull), se determina la distancia entre el centro del elemento InvoiceNumber detectado y el centro del nombre InvoiceHeader. Se calcula la diferencia (Rect.XCenter - InvoiceHeader.Rect.XCenter) y FlexiLayout Studio comprueba si esta diferencia pertenece al intervalo {-10000, 0, 0, 50000}*dt.
Esta descripción también tiene en cuenta la posibilidad de que el campo “Número de factura” esté situado debajo del nombre. En este caso, cuanto más separados estén los elementos entre sí, mayor será la penalización de la hipótesis correspondiente.
Las hipótesis que suponen que el número está a la derecha del nombre no se penalizarán tanto como aquellas que suponen que el número está debajo del nombre, porque la disposición “a la derecha” del campo “Número de factura” con respecto a su nombre es mucho más habitual.
Como se muestra en la imagen (b), con los parámetros especificados para los límites izquierdo y derecho del intervalo, la penalización máxima (1) corresponderá a un desplazamiento del campo “Número de factura” con respecto al campo del nombre de 10000dt hacia la izquierda o de 50000dt hacia la derecha.
Un desplazamiento de 1000 dots se penalizará con 0.1 si es un desplazamiento hacia la izquierda, o con 0.02 si es un desplazamiento hacia la derecha. Del mismo modo, un desplazamiento de 100 dots se penalizará con 0.01 si es un desplazamiento hacia la izquierda, o con 0.002 si es un desplazamiento hacia la derecha.
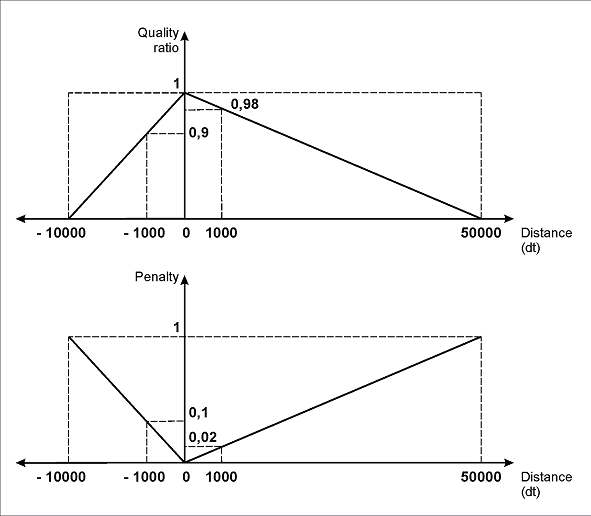
(b)
FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt; es idéntica a la anterior. Sin embargo, está reservada para los casos en que el campo “Número de factura” se encuentra en el mismo nivel horizontal que el campo del nombre, o incluso ligeramente por encima. Aquí, las penalizaciones son las mismas para cualquier desplazamiento vertical.
Los límites del intervalo se establecen siguiendo la misma lógica: dar prioridad a las hipótesis que encuentran el campo de datos a la derecha de su nombre. Sin embargo, el proyecto muestra que estos ajustes no impidieron detectar correctamente el número de factura incluso cuando estaba situado debajo del nombre (página 3).
Después de aplicar el emparejamiento del FlexiLayout a todas las páginas, puede ver que los dos campos buscados se han detectado correctamente.
En conclusión, la función FuzzyQuality es más eficiente y flexible que las funciones del grupo Nearest, lo cual es especialmente importante al procesar documentos semiestructurados.