Optimice la estructura y la búsqueda de FlexiLayout con elementos de grupo
Agrupe elementos relacionados para reducir las combinaciones de hipótesis y acelerar el emparejamiento de FlexiLayout, ilustrado paso a paso en el proyecto GroupSample.fsp.
Usar elementos de grupo para buscar objetos es lo más eficiente, porque agrupar elementos reduce el número de hipótesis de un elemento y acelera la búsqueda de la hipótesis resultante para todo el FlexiLayout. Además, si la agrupación de los elementos refleja la lógica del documento, ayuda a optimizar la estructura del FlexiLayout y a hacerla más explícita.Agrupar varios elementos en un único elemento de grupo permite que FlexiLayout Studio trate este conjunto de elementos como un todo con su propia hipótesis (compuesta por hipótesis individuales de los elementos del grupo).El análisis de las hipótesis y de sus elementos tiene lugar dentro del elemento de grupo, y solo el número de mejores hipótesis especificado por el usuario (1 de forma predeterminada) se usa en la búsqueda posterior de otros elementos.Todo el árbol de elementos puede considerarse un elemento de grupo, cuya mejor hipótesis es el resultado del emparejamiento del FlexiLayout.
El proyecto GroupSample.fsp (carpeta %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Group\Project1) muestra cómo se pueden usar los elementos de grupo. El objetivo es detectar los campos con el número de factura, la fecha de la factura y el importe de la factura en la imagen.
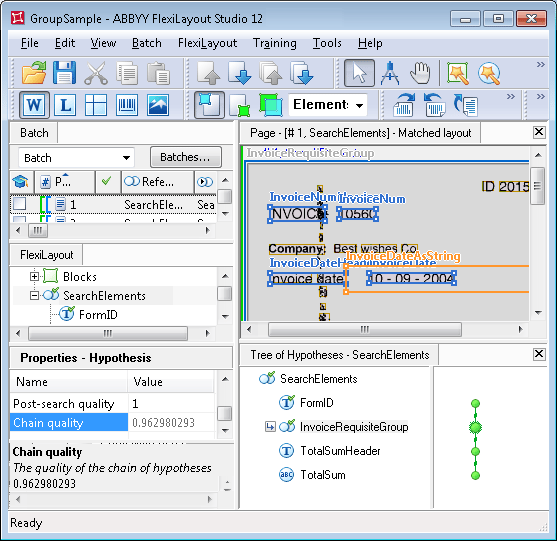
Agrupar los campos de facturas en InvoiceRequisiteGroup
Como muestra la imagen (y como suele ocurrir en los documentos financieros), el número y la fecha del documento son campos contiguos. Aunque la disposición de los campos en otro documento sea diferente, seguirán estando cerca entre sí.Además, están relacionados por la lógica del documento, ya que describen determinados datos bancarios y forman un bloque lógico. Para que la estructura del FlexiLayout sea más explícita, el proyecto los agrupa en un elemento de grupo llamado InvoiceRequisiteGroup.
Antes de agrupar los elementos, se creó un elemento identificador especial. (Los elementos identificadores se describen en detalle en Identificación y procesamiento de FlexiLayout en ABBYY FlexiCapture.) Este elemento se creó únicamente para ilustrar la “ramificación” del árbol de hipótesis provocada por la presencia o ausencia de elementos de grupo en él.Suponga que todos los elementos del árbol, excepto el elemento identificador, son opcionales y que sus hipótesis nulas tienen la calidad predeterminada de 0.97.
El primer elemento del grupo es un elemento de tipo texto estático, llamado InvoiceNumHeader, que describe las restricciones de búsqueda del nombre del campo “Número de factura”. La cadena “Invoice” se especifica como el valor de este elemento.A partir del análisis de las imágenes disponibles, el número de factura se busca a la derecha del nombre con ayuda de un elemento llamado InvoiceNum.De forma similar, debajo de la línea con el número de factura, el proyecto contiene un elemento para el campo de fecha, llamado InvoiceDateHeader. Para buscar la fecha propiamente dicha, el proyecto utiliza el grupo DateGroup con los siguientes subelementos: InvoiceDate y InvoiceDateAsString. Para obtener más información, consulte Búsqueda de fechas después de un reconocimiento de alta o baja calidad.Para detectar el campo con el importe de la factura, el proyecto utiliza dos elementos: un elemento texto estático llamado TotalSumHeader (su valor “Totalsum(EUR):” se escribe sin espacios) y un elemento cadena de caracteres llamado TotalSum, que busca directamente el importe.
La configuración de los elementos no se describe aquí. Puede consultarla directamente en el proyecto.
La cadena “Invoice”, especificada como valor del elemento InvoiceNumHeader, puede aparecer tres veces en las imágenes de prueba: como nombre del campo “Número de factura”, como subcadena del nombre del campo “Fecha de la factura” y en la parte inferior de la factura, como subcadena en las condiciones de la factura: “Current invoice is…”.Tenga en cuenta también que el nombre “INVOICE” (que el elemento InvoiceNumHeader debe detectar) tiene mucho ruido, lo que provocó un error en el nombre. En las otras líneas, la cadena “Invoice” es clara, y la calidad de las hipótesis correspondientes debe ser mayor que la de la hipótesis del nombre.
Cómo el grupo selecciona la mejor cadena de hipótesis
Ahora intente emparejar el FlexiLayout con las imágenes de prueba del lote.Una vez que haya iniciado el procedimiento de emparejamiento de FlexiLayout seleccionando el comando Match, verá que el árbol de hipótesis consta de una sola cadena.
El árbol de hipótesis consta de una sola cadena. La calidad del Grupo coincide con la calidad de la mejor cadena del Grupo.
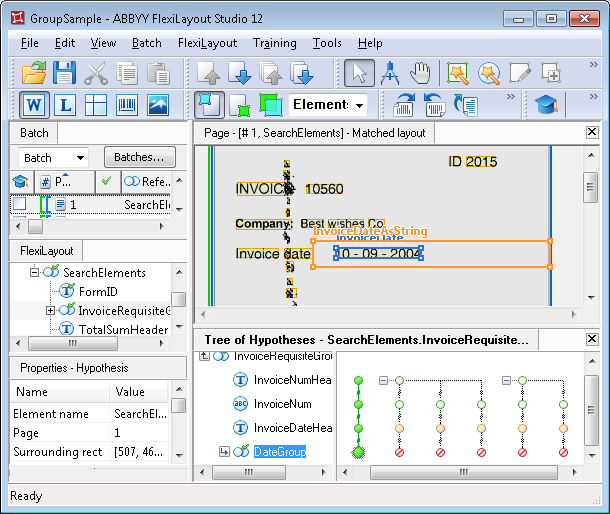
Haga doble clic en InvoiceRequisiteGroup para abrir su cuadro de diálogo de propiedades, donde podremos ver qué hipótesis se generaron para sus subelementos, qué cadena del Grupo resultó ser la mejor y por qué.Hay tres hipótesis para el elemento InvoiceNumHeader, igual que el número de cadenas “invoice” detectadas.La calidad de la hipótesis que nos interesa es inferior (aproximadamente 0.99), porque su área en la imagen tiene ruido y FlexiLayout Studio solo pudo reconocer “INVOIC” en lugar de “INVOICE”. La calidad de las otras dos hipótesis, en cambio, es máxima (calidad de la cadena = 1).Las propiedades del elemento InvoiceNum especifican que el número de factura puede tener cualquier cantidad de dígitos y debe buscarse a la derecha del nombre. En esta imagen, estas condiciones se cumplen en los tres casos, lo que permitió a FlexiLayout Studio seguir creando una cadena de hipótesis para cada una de las hipótesis del nombre del campo “Número de factura”.Aunque la Pre-search quality de cada una de las hipótesis del elemento InvoiceNum es 1, la cadena correcta sigue siendo la peor. Esto ocurre porque la calidad de la cadena se evalúa multiplicando las calidades de todas las hipótesis que forman la cadena.Para el nombre obligatorio, esta calidad es de aproximadamente 0.99. Si el Grupo no tuviera ningún otro elemento, la elección final en esta etapa sería incorrecta.
Post-search relations no se especifican para ninguno de los elementos, por lo que para cada elemento Post-search quality = 1, y puede juzgar la calidad de cualquier hipótesis por su Pre-search quality.
La búsqueda de la mejor hipótesis se realiza dentro del Grupo. Se analizan y comparan las calidades de todas las cadenas. La calidad del Grupo vendrá determinada por la calidad de la mejor cadena del Grupo.
Por qué la cadena correcta gana a pesar de una calidad inicial inferior
Como señalamos antes, en las propiedades del elemento InvoiceDateHeader especificamos que debía buscarse debajo de la línea con el número de factura. Sin embargo, ninguna de las cadenas con la mejor calidad (calidad de la cadena = 1) produjo una hipótesis para el nombre del campo de fecha. En consecuencia, se formaron hipótesis nulas en estas cadenas para el elemento InvoiceDateHeader. Como no cambiamos la calidad predeterminada de una hipótesis nula, la calidad de la cadena resultante de las cadenas correspondientes bajó a 0.97. Al mismo tiempo, el elemento correspondiente al nombre del campo de fecha se encontró para la cadena que tenía la calidad más baja. La calidad de su hipótesis es de aproximadamente 0.993. Es inferior a 1 porque la imagen en el área del nombre tiene ruido, lo que provocó un error de reconocimiento y una coincidencia incompleta entre el texto reconocido y el valor especificado en las propiedades del elemento InvoiceDateHeader. Como resultado, la hipótesis encontrada fue penalizada y su calidad final es de aproximadamente 0.98 (el resultado de multiplicar 0.99 por 0.993). No obstante, la calidad final de esta hipótesis es superior a la de las demás (0.97), por lo que en esta etapa esta cadena es la mejor.Para detectar el campo de fecha, el proyecto utiliza el elemento de grupo DateGroup, que especifica que al menos uno de los elementos no puede encontrarse si el otro se ha encontrado (se utilizó la función Dontfind).Como resultado de las características del diseño del documento y de las propiedades especificadas para el elemento InvoiceDateAsString (su alfabeto permite dígitos), FlexiLayout Studio logró encontrar el campo de fecha para todas las cadenas, aunque en realidad solo una de las tres hipótesis es correcta.Puesto que en cada grupo se ha encontrado uno de los elementos mientras que el otro no, la calidad final de la cadena en cada uno de los grupos DateGroup es 0.97 (1 multiplicado por 0.97, la calidad predeterminada de la hipótesis nula).En este ejemplo, la calidad final de las cadenas de DateGroup no afectará al “equilibrio” entre las hipótesis en el momento de detectar el elemento InvoiceDateHeader; es decir, la calidad de cada una de las cadenas se seguirá multiplicando por 0.97.Al final, FlexiLayout Studio generó una sola hipótesis para el elemento de grupo InvoiceRequisiteGroup, que corresponde a la mejor cadena del grupo. Su calidad es de aproximadamente 0.953; es decir, el “enfoque de grupo” ayudó a que ganara la hipótesis correcta, aunque su calidad inicial fuera inferior.
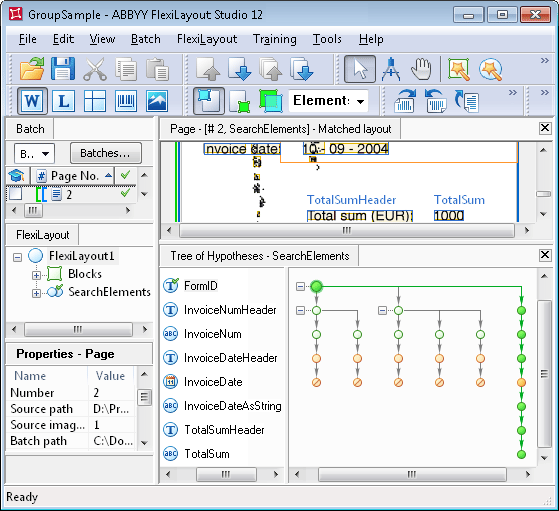
Para ver cómo sería el árbol de hipótesis sin elementos de grupo en FlexiLayout, abra el proyecto GroupSample.fsp en la carpeta Group\Project2. El árbol se muestra en la figura siguiente.Como se aprecia claramente en la figura, después de detectar el elemento FormID, el árbol de hipótesis se ramificó porque se generan varias hipótesis para el elemento InvoiceNumHeader. Como resultado, FlexiLayout Studio tiene que comparar los valores de calidad de cada una de las cadenas, comenzando cada vez por su primer elemento y descendiendo hasta el último.Además, para cualquier documento con un diseño más complejo que el de este ejemplo, un FlexiLayout sin elementos de grupo producirá un árbol de hipótesis con demasiadas ramas, lo que dificultará el emparejamiento de FlexiLayout.
Evite colocar todos los elementos buscados en un único grupo raíz. Esto solo es adecuado para FlexiLayouts muy simples con menos de 10 elementos, algo muy poco frecuente en tareas reales.Un aumento del número de elementos en el grupo raíz provoca un crecimiento masivo del número de hipótesis, hasta alcanzar el límite de 10.000 o agotar toda la memoria asignada al árbol de hipótesis. En cualquiera de los dos casos, el emparejamiento del FlexiLayout puede fallar.
En tareas reales, por lo general no es necesario explorar todas las combinaciones posibles de cada hipótesis de un elemento con cada hipótesis de todos los demás elementos, ya que la mayoría de los elementos pueden detectarse independientemente unos de otros.Por eso, debe agrupar los elementos en elementos de grupo lo más pequeños posible, para reducir el número de combinaciones que deben analizarse y acelerar la búsqueda.
Un árbol de hipótesis sin agrupar tiene demasiadas ramas y resulta difícil de analizar visualmente.
Además, dado que la calidad de la cadena final se calcula multiplicando los valores de calidad de todas las hipótesis de esa cadena, el volumen de cálculos puede ser mucho mayor en un árbol con demasiadas ramas, lo que hará que el emparejamiento de FlexiLayout sea más lento.