Para detectar varios títulos de documentos, tablas, campos o cualquier texto presente en todas o en la mayoría de las imágenes de un documento, FlexiLayout Studio utiliza un elemento especial de texto estático.
Si distintas imágenes procesadas por el mismo FlexiLayout tienen diferentes variantes de un mismo nombre (por ejemplo, el campo ‘Número de factura’ tiene las variantes ‘Factura’, ‘Factura:’ y ‘Núm. de factura’), debe especificar todos los valores posibles de texto estático, aunque solo difieran en los signos de puntuación.
Por qué debe enumerarse cada variante de texto estático
- Para generar una hipótesis correspondiente al valor especificado. Por ejemplo, si no especifica la variante Factura: y solo la variante Factura, los dos puntos no se incluirán en la hipótesis del nombre del campo. Entonces podrían quedar incluidos en el área de búsqueda del número de factura, que se busca a la derecha del nombre. Si la búsqueda del número permite caracteres no numéricos o no especificados, los dos puntos pueden acabar en la hipótesis del elemento que describe el número de factura.
- Para evitar penalizar una hipótesis por caracteres no especificados en la ventana Texto a buscar. Por ejemplo, si el valor Factura: se especifica en la sección Texto a buscar y el nombre Factura# también aparece en las imágenes procesadas, entonces, siempre que se permitan algunos errores para el elemento, se seguirá generando una hipótesis, pero su calidad se penalizará (en este ejemplo, el FlexiLayout permite al menos un error).
- Si hay hipótesis variantes disponibles, por ejemplo, Factura|Factura:, FlexiLayout Studio asignará a la hipótesis más larga una calidad ligeramente superior, de modo que la hipótesis Factura: será la preferida. Si se especifica una variante con dos puntos, la que no los tenga será penalizada en 0.001, porque la cadena Factura es una subcadena de Factura:. Penalizar la cadena más corta del nombre, que es una subcadena de la otra, hace que la hipótesis más larga sea la ganadora.
El proyecto de ejemplo StaticText.fsp
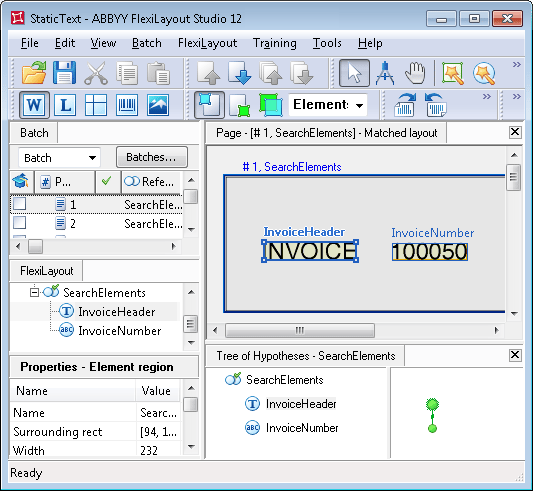
StaticText.fsp (carpeta %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Variants of StaticText) para ver cómo especificar los valores de un elemento de texto estático ayuda a detectar el nombre del campo Número de factura y el propio campo.
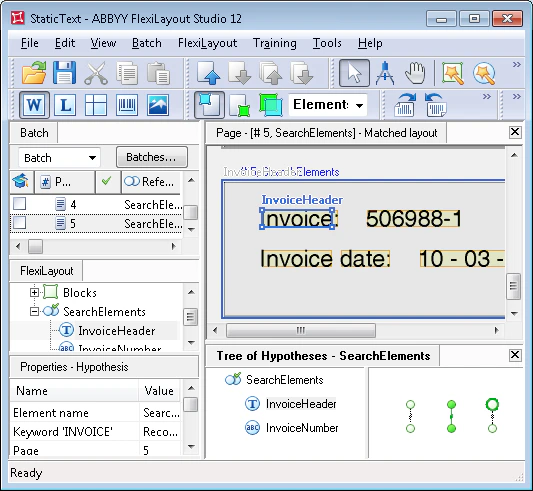
El proyecto tiene cinco páginas, cada una de las cuales muestra una variante del nombre del campo Número de factura.
En el cuadro de diálogo de Propiedades del elemento de texto estático llamado InvoiceHeader, hemos especificado todos los nombres posibles del campo que puede encontrarse en los documentos procesados. En este caso, son los valores mencionados anteriormente. El uso de mayúsculas y minúsculas en los nombres es irrelevante para la búsqueda: Factura|Factura:|Factura#:|Factura-.
Para acelerar la búsqueda del elemento, todas las variantes se escriben sin espacios. La ausencia o presencia de espacios no influye en la calidad de una hipótesis.
Elimine todos los valores excepto Factura y vuelva a hacer el emparejamiento
Restaure los valores y compare las hipótesis de la página 5