Si toutes les hypothèses de la chaîne d’éléments dans l’élément Group ont une qualité égale à 1, les autres hypothèses de ces éléments ne seront pas analysées.
Cela permet d’optimiser le FlexiLayout, d’accélérer la procédure de mise en correspondance et d’éviter la « ramification » indésirable de l’arbre des hypothèses. Cependant, une hypothèse optimale pour FlexiLayout Studio ne correspond pas forcément à l’objet recherché dans l’image.Cela peut se produire si les contraintes de recherche de l’élément ne sont pas suffisamment strictes. Lorsqu’une telle situation se présente, analysez d’abord les paramètres définis pour la recherche de l’élément.
Le projet d’exemple GO.fsp
GO.fsp (dossier %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\GO\1), dont l’objectif est de trouver le champ « Numéro de facture ».
Le projet comporte deux pages :
- Page 1 – La qualité de l’image est bonne.
- Page 2 – Le nom du champ recherché est parasité.
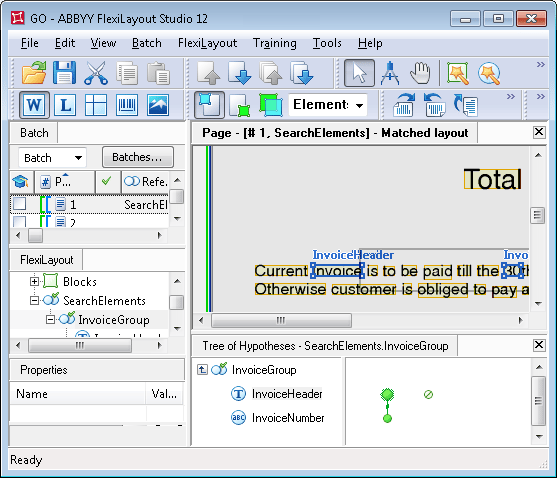
Le projet contient le groupe InvoiceGroup, qui contient l’élément utilisé pour rechercher le nom du champ : un élément Static Text nommé InvoiceHeader avec la valeur « INVOICE ».
Pour rechercher le champ « Numéro de facture » lui-même, le projet utilise un élément Character String nommé InvoiceNumber. Les contraintes de recherche du champ par rapport à son nom sont spécifiées dans la section Relations de l’élément InvoiceNumber.
La casse du nom dans la section Texte de recherche n’a pas d’importance.
Pourquoi la génération d’hypothèses s’arrête sur une chaîne de qualité 1
Pour afficher l’arbre d’hypothèses du groupe, double-cliquez sur le nom de l’élément Group dans l’arbre d’hypothèses, appuyez sur Entrée ou sélectionnez Afficher les détails dans le menu contextuel.
Ancrer le nom au bord droit de la page avec Nearest
Nearest: PageRight;.
Cela fonctionne parce que l’intitulé du champ recherché « Numéro de facture » est le seul élément le plus proche du bord droit de la page. Si ce n’était pas le cas, ou si le document n’avait pas une structure fixe, la fonction Nearest ne pourrait pas résoudre le problème.
Pénaliser les hypothèses de nombres éloignés avec FuzzyQuality
GO.fsp (dossier GO\2).
Comme vous pouvez le voir sur les images, la distance entre la chaîne de chiffres et le mot “invoice” est la plus faible dans le champ recherché “Numéro de facture”.
C’est le cas sur toutes les pages, ce qui permet d’influer sur les valeurs de qualité des hypothèses générées en saisissant le code suivant dans la section Advanced post-search relations de l’élément InvoiceNumber :
Cela signifie que si les deux éléments sont détectés, la distance entre eux est calculée pour l’hypothèse de l’élément InvoiceNumber, et FlexiLayout Studio vérifie si elle appartient à l’intervalle {0, 0, 0, 10000}*dt.
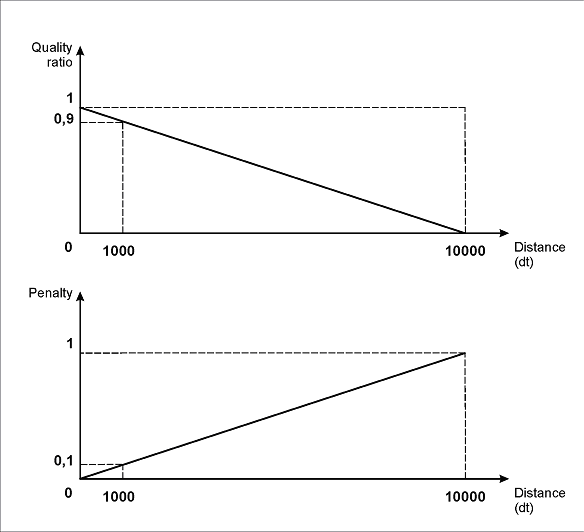
Cette description de l’intervalle montre la dépendance linéaire entre la qualité de l’hypothèse et la distance entre les éléments : plus la distance est grande, plus la pénalité est élevée (la fonction FuzzyQuality renvoie la Post-search quality de l’hypothèse ; celle-ci est visible dans la fenêtre Properties de l’hypothèse).
La valeur de la limite droite de l’intervalle (10000dt) a été déterminée expérimentalement. Lors du choix de cette valeur, vous devez tenir compte de la distance entre les objets correspondants sur les images de test.
Comme le montre la figure suivante, avec les propriétés d’intervalle spécifiées, la pénalité maximale (1) correspondra à une distance de 10000dt. En conséquence, une distance de 1000dt entraînera une pénalité de 0.1, une distance de 100dt, une pénalité de 0.01, et ainsi de suite.
Ainsi, pour des distances réelles d’environ 100 à 300 dots, visibles sur les images, le coefficient de pénalité sera de 0.99 à 0.97.
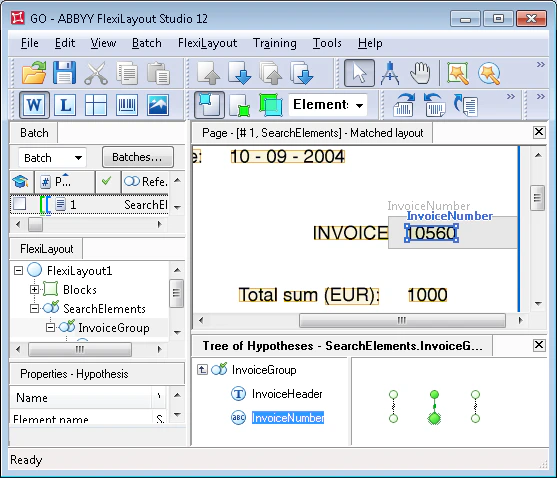
Pour les images de ce batch, l’hypothèse correspondant au champ indésirable “Numéro de facture” avec la valeur “2005” a reçu la pénalité maximale, tandis que l’hypothèse correspondant au champ recherché a reçu la pénalité minimale.
Comme la pénalisation a rendu la Post-search quality de toutes les hypothèses différente de 1, toutes les hypothèses des deux éléments de l’élément Group InvoiceGroup seront désormais analysées.
Notez que le champ “Numéro de facture” a été correctement détecté même sur la page 2, où le mot “Invoice” est très bruité, ce qui a provoqué une erreur de reconnaissance et, par conséquent, des pénalités supplémentaires pour l’hypothèse.