8 peut être reconnu comme B, 7 comme ?, 5 comme S et 4 comme H ou comme la combinaison de lettres LI. Cela peut se produire si les chiffres sont « collés », ce qui est fréquent lorsque les documents sont remplis à la machine à écrire.
Ajouter les caractères mal reconnus à l’alphabet
Il n’est pas nécessaire de spécifier toutes les variantes de reconnaissance possibles. Si la qualité des images est mauvaise, trouver toutes ces variantes peut prendre énormément de temps.Si, en raison de la faible qualité des images, les résultats de la reconnaissance sont imprévisibles, vous devez lancer la recherche en utilisant d’autres propriétés de l’élément, telles que la longueur de la chaîne et la longueur des espaces dans la chaîne.
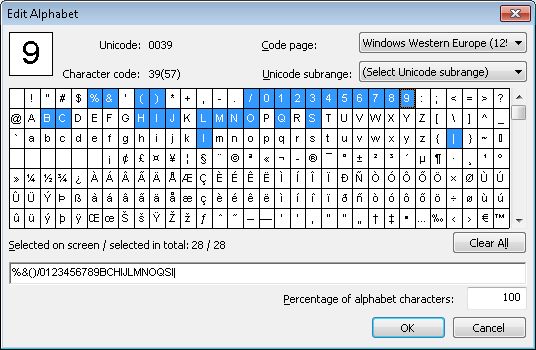
Mise en correspondance avec un alphabet composé uniquement de chiffres
1.fsp (dossier Digital strings\Project1).
Le projet comporte trois pages, chacune avec une erreur de reconnaissance différente :
Pour détecter la chaîne de chiffres, le projet utilise un élément Character String nommé DigitalString, dont l’alphabet ne contient que des chiffres. Le pourcentage maximal de caractères non numériques est défini à 20 %.
Après avoir exécuté la procédure de mise en correspondance sur toutes les pages, le champ de chiffres de la page 3 n’a pas été entièrement détecté. La valeur de qualité de l’hypothèse est d’environ 0.98. Sur les pages 1 et 2, la chaîne a été détectée. Cependant, comme elle contient des caractères hors alphabet, les hypothèses correspondantes ont été pénalisées, et leur qualité est respectivement de 0.978 et 0.982.
Nouvelle mise en correspondance avec l’alphabet étendu
L, I, e, a, B, S) sont ajoutés à l’alphabet.
Le résultat de la mise en correspondance est visible dans le projet 2.fsp (dossier %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Digital strings\Project2).
Les autres paramètres des projets sont identiques.
Comme vous pouvez le voir, la chaîne de la page 3 a été entièrement détectée, et la qualité de toutes les hypothèses générées est de 1.