Optimiser la structure et la recherche d’un FlexiLayout avec les éléments Group
Regroupez les éléments associés afin de réduire les combinaisons d’hypothèses et d’accélérer la mise en correspondance du FlexiLayout, avec une illustration pas à pas dans le projet GroupSample.fsp.
L’utilisation des éléments Group pour rechercher des objets est la méthode la plus efficace, car le regroupement des éléments réduit le nombre d’hypothèses pour un élément et accélère la recherche de l’hypothèse résultante pour l’ensemble du FlexiLayout. En outre, si le regroupement des éléments reflète la logique du document, il contribue à optimiser la structure du FlexiLayout et à la rendre plus explicite.Le regroupement de plusieurs éléments en un seul élément Group permet à FlexiLayout Studio de traiter cet ensemble d’éléments comme un tout, avec sa propre hypothèse (composée des hypothèses individuelles des éléments du groupe).L’analyse des hypothèses et de leurs éléments s’effectue dans l’élément Group, et seul le nombre d’hypothèses les plus probables spécifié par l’utilisateur (1 par défaut) est utilisé lors de la recherche ultérieure d’autres éléments.L’ensemble de l’arborescence des éléments peut être considéré comme un seul élément Group, dont la meilleure hypothèse constitue le résultat de la mise en correspondance du FlexiLayout.
Le projet GroupSample.fsp (dossier %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Group\Project1) montre comment les éléments Group peuvent être utilisés. L’objectif est de détecter les champs contenant le numéro de facture, la date de la facture et le montant de la facture sur l’image.
Regrouper les champs de la facture dans InvoiceRequisiteGroup
Comme le montre l’image (et comme c’est généralement le cas pour tous les documents financiers), le numéro et la date du document sont des champs voisins. Même si la disposition des champs sur un autre document est différente, ils resteront proches l’un de l’autre.En outre, ils sont liés par la logique du document, car ils décrivent certaines informations bancaires et forment un bloc logique. Pour rendre la structure du FlexiLayout plus explicite, le projet les regroupe dans un élément Group nommé InvoiceRequisiteGroup.
Avant de regrouper les éléments, un élément d’identification spécial a été créé. (Les éléments d’identification sont décrits en détail dans Identification et traitement des FlexiLayouts dans ABBYY FlexiCapture.) Cet élément a été créé uniquement pour illustrer la « ramification » de l’arbre des hypothèses due à la présence ou à l’absence d’éléments Group.Supposons que tous les éléments de l’arbre, à l’exception de l’élément d’identification, soient facultatifs et que leurs hypothèses nulles aient la qualité par défaut de 0.97.
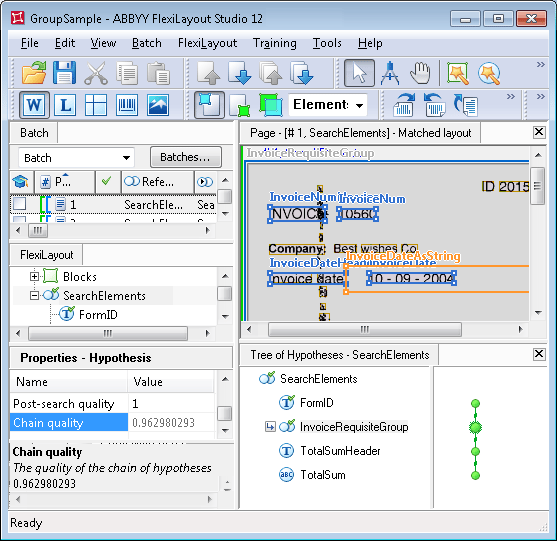
Le premier élément du Group est un élément de type Static Text, nommé InvoiceNumHeader, qui décrit les search constraints pour le nom du champ “Numéro de facture”. La string “Invoice” est spécifiée comme valeur de cet élément.D’après l’analyse des images disponibles, le numéro de facture est recherché à droite du nom, à l’aide d’un élément nommé InvoiceNum.De même, sous la ligne contenant le numéro de facture, le projet contient un élément pour le champ de date, nommé InvoiceDateHeader. Pour rechercher la date proprement dite, le projet utilise le groupe DateGroup avec les sous-éléments suivants : InvoiceDate et InvoiceDateAsString. Pour plus d’informations, voir Recherche de date après une reconnaissance de qualité élevée ou faible.Pour détecter le champ contenant le montant de la facture, le projet utilise deux éléments : un élément Static Text nommé TotalSumHeader (sa valeur “Totalsum(EUR):” est écrite sans espaces) et un élément Character String nommé TotalSum, qui recherche directement le montant.
Les paramètres des éléments ne sont pas décrits ici. Vous pouvez les consulter directement dans le projet.
La string “Invoice”, spécifiée comme valeur de l’élément InvoiceNumHeader, peut apparaître trois fois dans les images de test : comme nom du champ “Numéro de facture”, comme sous-chaîne du nom du champ “Invoice date” et, en bas de la facture, comme sous-chaîne dans les conditions de la facture : “Current invoice is…”.Notez également que le nom “INVOICE” (que l’élément InvoiceNumHeader est censé détecter) est très bruité, ce qui a entraîné une erreur dans le nom. Dans les autres lignes, la string “Invoice” est claire, et la qualité des hypothèses correspondantes doit être supérieure à celle de l’hypothèse pour ce nom.
Comment le Group sélectionne la meilleure chaîne d’hypothèses
Essayez maintenant de mettre en correspondance le FlexiLayout avec les images de test du lot.Une fois la procédure de mise en correspondance de FlexiLayout lancée en sélectionnant la commande Associer, vous verrez que l’arbre d’hypothèses se compose d’une seule chaîne.
L’arbre d’hypothèses se compose d’une seule chaîne. La qualité du Group correspond à celle de la meilleure chaîne du Group.
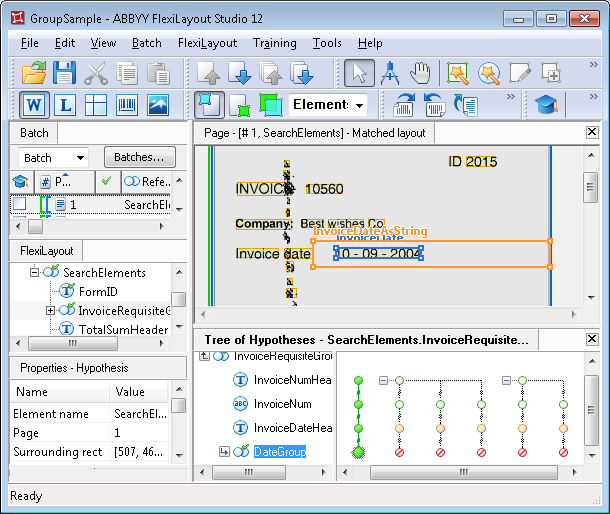
Double-cliquez sur InvoiceRequisiteGroup pour ouvrir sa boîte de dialogue Propriétés, où vous pouvez voir quelles hypothèses ont été générées pour ses sous-éléments, quelle chaîne du Group s’est révélée la meilleure et pourquoi.Il y a trois hypothèses pour l’élément InvoiceNumHeader, soit autant que d’occurrences de la chaîne « invoice » détectées.La qualité de l’hypothèse qui nous intéresse est plus faible (environ 0.99), car sa zone sur l’image est bruitée et ABBYY FlexiLayout Studio n’a pu reconnaître que « INVOIC » au lieu de « INVOICE ». La qualité des deux autres hypothèses, en revanche, est maximale (qualité de la chaîne = 1).Les propriétés de l’élément InvoiceNum spécifient que le numéro de facture peut comporter un nombre quelconque de chiffres et doit être recherché à droite de l’intitulé. Sur cette image, ces conditions sont remplies dans les trois cas, ce qui a permis à ABBYY FlexiLayout Studio de continuer à créer une chaîne d’hypothèses pour chacune des hypothèses du nom du champ « Numéro de facture ».Bien que la Pre-search quality de chacune des hypothèses de l’élément InvoiceNum soit de 1, la chaîne correcte reste la moins bonne. Cela s’explique par le fait que la qualité de la chaîne est évaluée en multipliant les qualités de toutes les hypothèses qui la composent.Pour le nom obligatoire, cette qualité est d’environ 0.99. Si le Group n’avait contenu aucun autre élément, le choix final à ce stade aurait été incorrect.
Aucune Post-search relations n’est spécifiée pour les éléments, donc pour chacun d’eux la Post-search quality = 1, et vous pouvez évaluer la qualité d’une hypothèse donnée à partir de sa Pre-search quality.
La recherche de la meilleure hypothèse s’effectue au sein du Group. La qualité de toutes les chaînes est analysée et comparée. La qualité du Group est déterminée par la qualité de la meilleure chaîne du Group.
Pourquoi la chaîne correcte l’emporte malgré une qualité initiale plus faible
Comme nous l’avons indiqué plus haut, dans les propriétés de l’élément InvoiceDateHeader, nous avons spécifié qu’il devait être recherché sous la ligne contenant le numéro de facture. Cependant, aucune des chaînes de meilleure qualité (qualité de la chaîne = 1) n’a donné d’hypothèse pour le nom du champ de date. Par conséquent, des hypothèses nulles ont été formées dans ces chaînes pour l’élément InvoiceDateHeader.Comme la qualité par défaut d’une hypothèse nulle n’a pas été modifiée, la qualité de la chaîne des chaînes correspondantes est tombée à 0.97. En même temps, l’élément correspondant au nom du champ de date a été trouvé pour la chaîne qui avait la qualité la plus faible. La qualité de son hypothèse est d’environ 0.993.Elle est inférieure à 1 parce que l’image dans la zone du nom est bruitée, ce qui a entraîné une erreur de reconnaissance et une correspondance incomplète entre le texte reconnu et la valeur spécifiée dans les propriétés de l’élément InvoiceDateHeader. Par conséquent, l’hypothèse trouvée a été pénalisée et sa qualité finale est d’environ 0.98 (résultat de la multiplication de 0.99 par 0.993).Néanmoins, la qualité finale de cette hypothèse est supérieure à celle des autres (0.97), de sorte qu’à ce stade, cette chaîne est la meilleure.Pour détecter le champ de date, le projet utilise l’élément Group DateGroup, qui spécifie qu’au moins un des éléments ne peut pas être trouvé si l’autre a été trouvé (la fonction Dontfind a été utilisée).En raison des caractéristiques de mise en page du document et des propriétés spécifiées pour l’élément InvoiceDateAsString (son alphabet autorise les chiffres), FlexiLayout Studio a réussi à trouver le champ de date pour toutes les chaînes, bien qu’une seule des trois hypothèses soit réellement correcte.Comme dans chaque Group l’un des éléments a été trouvé alors que l’autre ne l’a pas été, la qualité finale de la chaîne dans chacun des groupes DateGroup est de 0.97 (1 multiplié par 0.97, la qualité par défaut de l’hypothèse nulle).Dans cet exemple, la qualité finale des chaînes DateGroup n’affectera pas l’« équilibre » entre les hypothèses au moment de la détection de l’élément InvoiceDateHeader ; autrement dit, la qualité de chacune des chaînes est simplement multipliée une nouvelle fois par 0.97.Au final, FlexiLayout Studio a généré une seule hypothèse pour l’élément Group InvoiceRequisiteGroup, qui correspond à la meilleure chaîne du Group. Sa qualité est d’environ 0.953, c’est-à-dire que l’« approche par groupe » a permis à la bonne hypothèse de l’emporter, même si sa qualité initiale était plus faible.
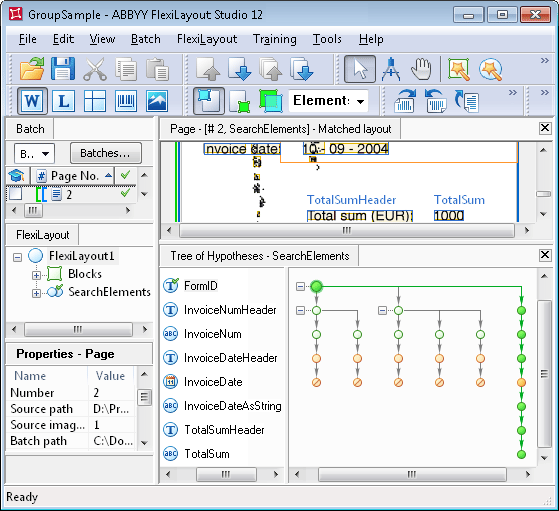
Pour voir à quoi ressemblerait l’arbre d’hypothèses sans éléments Group dans le FlexiLayout, ouvrez le projet GroupSample.fsp dans le dossier Group\Project2. L’arbre est présenté dans la figure suivante.Comme on le voit clairement sur la figure, après la détection de l’élément FormID, l’arbre d’hypothèses s’est ramifié, car plusieurs hypothèses sont générées pour l’élément InvoiceNumHeader. Par conséquent, FlexiLayout Studio doit comparer la qualité de chacune des chaînes, en repartant chaque fois de leur tout premier élément pour descendre jusqu’au dernier.En outre, pour tout document dont la mise en page est plus complexe que celle de cet exemple, un FlexiLayout sans éléments Group produira un arbre d’hypothèses avec trop de branches, ce qui compliquera la mise en correspondance du FlexiLayout.
Évitez de placer tous les éléments recherchés dans un seul groupe racine. Cela ne convient qu’à des FlexiLayouts très simples comportant moins de 10 éléments, ce qui est très rare dans des tâches réelles.L’augmentation du nombre d’éléments dans le Group racine entraîne une forte croissance du nombre d’hypothèses, jusqu’à atteindre la limite de 10 000 ou à épuiser toute la mémoire allouée à l’arbre d’hypothèses. Dans un cas comme dans l’autre, la mise en correspondance du FlexiLayout peut échouer.
Dans des tâches réelles, il n’est généralement pas nécessaire d’explorer toutes les combinaisons possibles de chaque hypothèse d’un élément avec chaque hypothèse de tous les autres éléments, car la plupart des éléments peuvent être détectés indépendamment les uns des autres.C’est pourquoi il est conseillé de regrouper les éléments en éléments Group aussi petits que possible, afin de réduire le nombre de combinaisons à analyser et d’accélérer la recherche.
Un arbre d’hypothèses non groupé comporte trop de branches et son analyse visuelle est difficile.
De plus, comme la qualité de la chaîne finale est calculée en multipliant les qualités de toutes les hypothèses de cette chaîne, le volume de calculs peut être bien plus élevé dans un arbre comportant trop de branches, ce qui ralentira la mise en correspondance du FlexiLayout.