Wenn alle Hypothesen der Elementkette im Gruppenelement den Quality-Wert 1 haben, werden die übrigen Hypothesen dieser Elemente nicht analysiert.
Dies geschieht, um das FlexiLayout zu optimieren, das Matching-Verfahren zu beschleunigen und eine unerwünschte „Verzweigung“ des Hypothesenbaums zu vermeiden. Eine Hypothese, die für FlexiLayout Studio optimal ist, entspricht jedoch nicht unbedingt dem im Bild gesuchten Objekt.Das kann passieren, wenn die Suchbedingungen für das Element nicht streng genug sind. Wenn eine solche Situation eintritt, analysieren Sie zuerst die für die Elementsuche festgelegten Parameter.
Das Beispielprojekt GO.fsp
GO.fsp (Ordner %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\GO\1), dessen Ziel es ist, das Feld „Rechnungsnummer“ zu finden.
Das Projekt hat zwei Seiten:
- Seite 1 – Die Bildqualität ist gut.
- Seite 2 – Der Name des gesuchten Felds ist verrauscht.
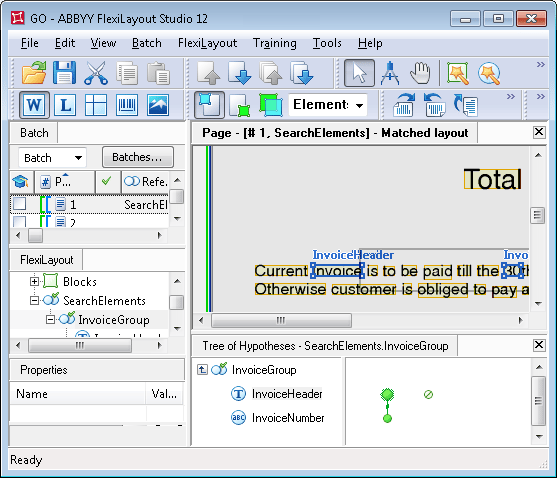
Das Projekt enthält die Gruppe InvoiceGroup, die das Element enthält, das zur Suche nach dem Feldnamen verwendet wird: ein Static Text-Element namens InvoiceHeader mit dem Wert „INVOICE“.
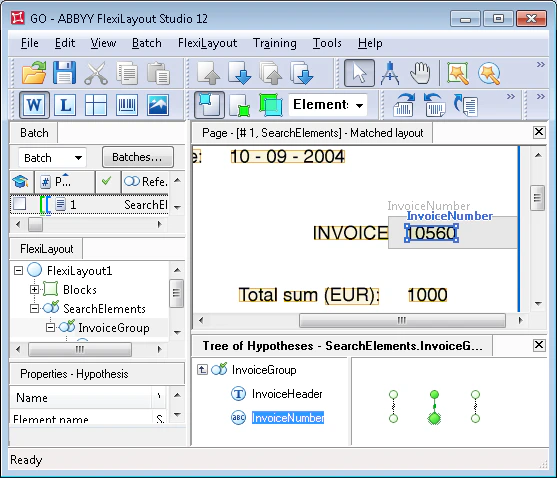
Um nach dem Feld „Rechnungsnummer“ selbst zu suchen, verwendet das Projekt ein Zeichenkette-Element namens InvoiceNumber. Die Suchbedingungen für das Feld relativ zum Namen sind im Abschnitt Beziehungen des Elements InvoiceNumber angegeben.
Die Groß-/Kleinschreibung des Namens im Abschnitt Search text ist unerheblich.
Warum die Hypothesengenerierung bei einer Kette mit Quality 1 stoppt
Um den Hypothesenbaum der Gruppe anzuzeigen, doppelklicken Sie im Hypothesenbaum auf den Namen des Elements Gruppenelement, drücken Sie Enter oder wählen Sie im Kontextmenü Show Details aus.
Verankern Sie den Namen mit Nearest am rechten Seitenrand
Nearest: PageRight;.
Das funktioniert, weil die Bezeichnung des gesuchten Felds „Rechnungsnummer“ das einzige Element ist, das dem rechten Seitenrand am nächsten liegt. Wäre das nicht der Fall oder wäre das Dokument nicht standardisiert, könnte die Funktion Nearest das Problem nicht lösen.
Weit entfernte Zahlenhypothesen mit FuzzyQuality abwerten
GO.fsp (Ordner GO\2) gezeigt.
Wie Sie auf den Bildern sehen können, ist der Abstand zwischen der Ziffernfolge und dem Wort “invoice” im gesuchten Feld “Rechnungsnummer” am geringsten.
Das gilt auf allen Seiten, wodurch wir die Quality-Werte der erzeugten Hypothesen beeinflussen können, indem wir den folgenden Code im Abschnitt Erweiterte Nach-Suchbeziehungen des Elements InvoiceNumber eingeben:
Das bedeutet, dass, wenn beide Elemente erkannt werden, für die Hypothese des Elements InvoiceNumber der Abstand zwischen den Elementen berechnet wird und FlexiLayout Studio prüft, ob er in das Intervall {0, 0, 0, 10000}*dt fällt.
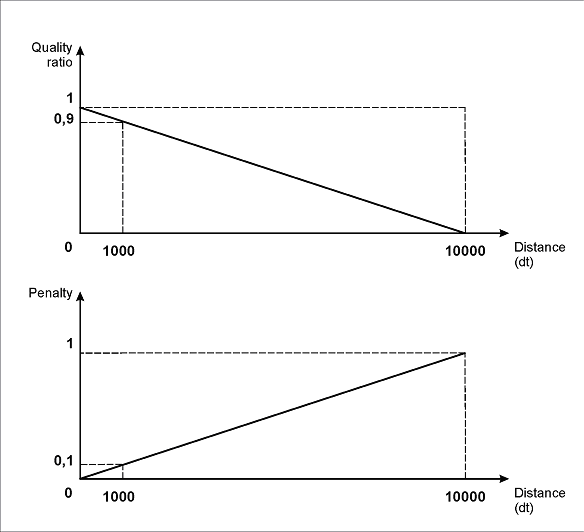
Diese Beschreibung des Intervalls zeigt die lineare Abhängigkeit zwischen der Quality der Hypothese und dem Abstand zwischen den Elementen: Je größer der Abstand, desto höher die Abwertung (die Funktion FuzzyQuality gibt die Post-search quality der Hypothese zurück, die im Properties-Fenster der Hypothese zu sehen ist).
Der Wert für die rechte Grenze des Intervalls (10000dt) wurde experimentell ermittelt. Bei der Wahl dieses Werts sollten Sie den Abstand zwischen den entsprechenden Objekten auf Testbildern berücksichtigen.
Wie aus der folgenden Abbildung hervorgeht, entspricht bei den angegebenen Intervalleigenschaften die maximale Abwertung (1) einem Abstand von 10000dt. Entsprechend führt ein Abstand von 1000dt zu einer Abwertung von 0.1, ein Abstand von 100dt zu einer Abwertung von 0.01 usw.
Bei realen Abständen von etwa 100–300 Dots, die auf den Bildern zu sehen sind, beträgt der Abwertungskoeffizient also 0.99–0.97.
Für die Bilder in diesem Batch erhielt die Hypothese, die dem unerwünschten Feld “Rechnungsnummer” mit dem Wert “2005” entspricht, die maximale Abwertung, während die Hypothese für das gesuchte Feld die minimale Abwertung erhielt.
Da die Abwertung dazu führte, dass die Post-search quality aller Hypothesen nicht mehr 1 ist, werden nun alle Hypothesen beider Elemente des Group-Elements InvoiceGroup analysiert.
Beachten Sie, dass das Feld “Rechnungsnummer” sogar auf Seite 2 korrekt erkannt wurde, wo die Bezeichnung “Invoice” stark verrauscht ist, was einen Erkennungsfehler und folglich zusätzliche Abwertungen für die Hypothese verursachte.