Optimieren Sie die FlexiLayout-Struktur und -Suche mit Gruppenelementen
Gruppieren Sie zusammengehörige Elemente, um Hypothesenkombinationen zu reduzieren und den Abgleich des FlexiLayouts zu beschleunigen, Schritt für Schritt veranschaulicht im Projekt GroupSample.fsp.
Die Verwendung von Gruppenelementen für die Suche nach Objekten ist am effizientesten, da das Gruppieren von Elementen die Anzahl der Hypothesen für ein Element reduziert und die Suche nach der resultierenden Hypothese für das gesamte FlexiLayout beschleunigt. Wenn die Gruppierung der Elemente außerdem die Logik des Dokuments widerspiegelt, trägt dies dazu bei, die Struktur des FlexiLayouts zu optimieren und klarer zu machen.Wenn mehrere Elemente zu einem Gruppenelement zusammengefasst werden, kann FlexiLayout Studio diese Elementmenge als Ganzes mit einer eigenen Hypothese behandeln (die sich aus den einzelnen Hypothesen für die Elemente in der Group zusammensetzt).Die Analyse der Hypothesen und ihrer Elemente erfolgt innerhalb des Gruppenelements, und nur die vom Benutzer angegebene Anzahl der besten Hypothesen (standardmäßig 1) wird bei der anschließenden Suche nach anderen Elementen verwendet.Der gesamte Elementbaum kann als ein Gruppenelement betrachtet werden, dessen beste Hypothese das Ergebnis des Abgleichs des FlexiLayouts ist.
Das Projekt GroupSample.fsp (Ordner %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Group\Project1) zeigt, wie Gruppenelemente verwendet werden können. Ziel ist es, die Felder mit der Rechnungsnummer, dem Rechnungsdatum und der Rechnungssumme im Bild zu erkennen.
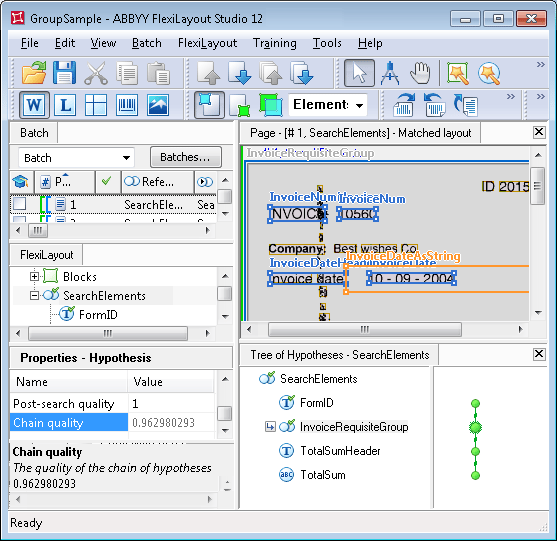
Gruppieren der Rechnungsfelder in InvoiceRequisiteGroup
Wie das Bild zeigt (und wie es bei Finanzdokumenten in der Regel der Fall ist), sind Nummer und Datum des Dokuments benachbarte Felder. Selbst wenn die Anordnung der Felder in einem anderen Dokument anders ist, liegen sie dennoch nahe beieinander.Außerdem sind sie durch die Logik des Dokuments miteinander verbunden, da sie bestimmte Angaben beschreiben und einen logischen Block bilden. Um die Struktur des FlexiLayouts deutlicher zu machen, gruppiert das Projekt sie in einem Gruppenelement mit dem Namen InvoiceRequisiteGroup.
Bevor die Elemente gruppiert wurden, wurde ein spezielles Bezeichnerelement erstellt. (Bezeichnerelemente werden ausführlich in Identifizierung und Verarbeitung von FlexiLayouts in ABBYY FlexiCapture beschrieben.) Dieses Element wurde nur erstellt, um die „Verzweigung“ des Hypothesenbaums zu veranschaulichen, die durch das Vorhandensein oder Fehlen von Gruppenelementen verursacht wird.Gehen Sie davon aus, dass alle Elemente im Baum mit Ausnahme des Bezeichnerelements optional sind und ihre Nullhypothesen die Standardqualität 0.97 haben.
Das erste Element in der Gruppe ist ein Element vom Typ Static Text mit dem Namen InvoiceNumHeader, das die Suchbedingungen für die Bezeichnung des Felds „Rechnungsnummer“ beschreibt. Die Zeichenkette „Invoice“ ist als Wert dieses Elements angegeben.Auf Grundlage einer Analyse der verfügbaren Bilder wird die Rechnungsnummer rechts von dieser Bezeichnung mithilfe eines Elements mit dem Namen InvoiceNum gesucht.Ebenso enthält das Projekt unter der Zeile mit der Rechnungsnummer ein Element für das Datumsfeld mit dem Namen InvoiceDateHeader. Um nach dem Datum selbst zu suchen, verwendet das Projekt die Gruppe DateGroup mit den folgenden Subelementen: InvoiceDate und InvoiceDateAsString. Weitere Informationen finden Sie unter Suche nach Datumsangaben nach Erkennung mit hoher oder niedriger Qualität.Um das Feld mit der Rechnungssumme zu erkennen, verwendet das Projekt zwei Elemente: ein Static Text-Element mit dem Namen TotalSumHeader (sein Wert „Totalsum(EUR):“ wird ohne Leerzeichen geschrieben) und ein Character String-Element mit dem Namen TotalSum, das direkt nach der Summe sucht.
Die Einstellungen der Elemente werden hier nicht beschrieben. Sie können sie direkt im Projekt nachschlagen.
Der String „Invoice“, der als Wert des Elements InvoiceNumHeader angegeben ist, kann auf den Testbildern dreimal vorkommen: als Bezeichnung des Felds „Rechnungsnummer“, als Teilzeichenfolge in der Bezeichnung des Felds „Rechnungsdatum“ und unten auf der Rechnung als Teilzeichenfolge in den Rechnungsbedingungen: „Current invoice is…“.Beachten Sie auch, dass die Bezeichnung „INVOICE“ (die das Element InvoiceNumHeader erkennen soll) stark verrauscht ist, was zu einem Fehler in der Bezeichnung geführt hat. In den anderen Zeilen ist der String „Invoice“ deutlich, und die Quality der entsprechenden Hypothesen muss höher sein als die der Hypothese für die Bezeichnung.
Versuchen Sie nun, das FlexiLayout mit den Testbildern im Batch abzugleichen.Sobald Sie den Abgleich des FlexiLayouts durch Auswahl des Befehls Match gestartet haben, sehen Sie, dass der Hypothesenbaum aus einer einzigen Kette besteht.
Der Hypothesenbaum besteht nur aus einer einzigen Kette. Die Qualität der Group entspricht der Qualität der besten Kette in der Group.
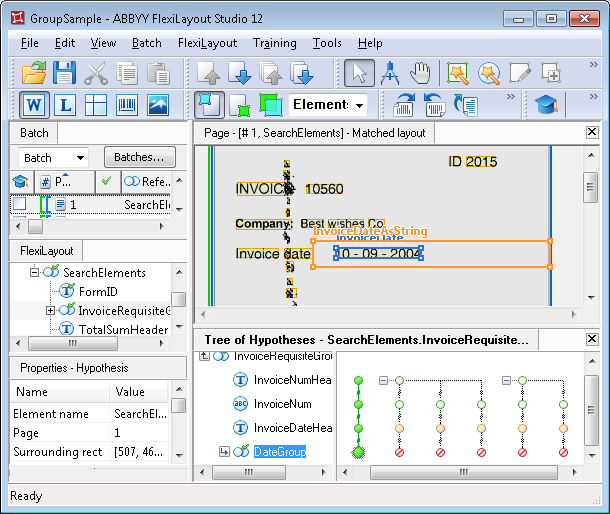
Doppelklicken Sie auf InvoiceRequisiteGroup, um das Dialogfeld „Eigenschaften“ zu öffnen. Dort können Sie sehen, welche Hypothesen für die Subelemente erzeugt wurden, welche Kette in der Group die beste war und warum.Es gibt für das Element InvoiceNumHeader drei Hypothesen, entsprechend der Anzahl der erkannten „invoice“-strings.Die Qualität der Hypothese, die uns interessiert, ist niedriger (ungefähr 0,99), weil ihr Bereich im Bild verrauscht ist und FlexiLayout Studio nur „INVOIC“ statt „INVOICE“ erkennen konnte. Die Qualität der beiden anderen Hypothesen ist dagegen maximal (Chain quality = 1).Die Eigenschaften des Elements InvoiceNum legen fest, dass die Rechnungsnummer aus beliebig vielen Ziffern bestehen kann und rechts vom Namen gesucht werden soll. In diesem Bild sind diese Bedingungen in allen drei Fällen erfüllt, sodass FlexiLayout Studio für jede Hypothese für den Namen des Felds „Invoice number“ eine Kette von Hypothesen weiter aufbauen konnte.Obwohl die Pre-search quality jeder Hypothese des Elements InvoiceNum 1 beträgt, ist die korrekte Kette trotzdem die schlechteste. Das liegt daran, dass die Chain quality durch Multiplikation der Qualität aller Hypothesen bestimmt wird, aus denen die Kette besteht.Für den erforderlichen Namen beträgt diese Qualität etwa 0,99. Hätte die Group keine weiteren Elemente, wäre die endgültige Auswahl in dieser Phase falsch.
Post-search relations sind für keines der Elemente angegeben, daher gilt für jedes Element Post-search quality = 1, und Sie können die Qualität einer beliebigen Hypothese anhand ihrer Pre-search quality beurteilen.
Die Suche nach der besten Hypothese erfolgt innerhalb der Group. Die Qualität aller Ketten wird analysiert und verglichen. Die Qualität der Group wird durch die Qualität der besten Kette in der Group bestimmt.
Warum die korrekte Kette trotz geringerer anfänglicher Qualität gewinnt
Wie wir oben erwähnt haben, haben wir in den Eigenschaften des Elements InvoiceDateHeader angegeben, dass es unter der Zeile mit der Rechnungsnummer gesucht werden soll. Keine der Ketten mit der besten Qualität (Chain quality = 1) ergab jedoch eine Hypothese für den Namen des Datumsfelds. Folglich wurden in diesen Ketten Nullhypothesen für das Element InvoiceDateHeader gebildet.Da wir die Standardqualität einer Nullhypothese nicht geändert haben, sank die resultierende Chain quality der entsprechenden Ketten auf 0,97. Gleichzeitig wurde das Element, das dem Namen des Datumsfelds entspricht, in der Kette gefunden, die die niedrigste Qualität hatte. Die Qualität seiner Hypothese beträgt ungefähr 0,993.Sie ist kleiner als 1, weil das Bild im Bereich des Namens verrauscht ist, was zu einem Erkennungsfehler und zu einer unvollständigen Übereinstimmung zwischen dem erkannten Text und dem in den Eigenschaften des Elements InvoiceDateHeader angegebenen Wert führte. Dadurch wurde die gefundene Hypothese abgewertet, und ihre endgültige Qualität beträgt etwa 0,98 (das Ergebnis der Multiplikation von 0,99 mit 0,993).Dennoch ist die endgültige Qualität dieser Hypothese höher als die der anderen (0,97), sodass diese Kette in dieser Phase die beste ist.Um das Datumsfeld zu erkennen, verwendet das Project das Gruppenelement DateGroup, das festlegt, dass mindestens eines der Elemente nicht gefunden werden darf, wenn das andere gefunden wurde (dazu wurde die Funktion Dontfind verwendet).Aufgrund der Besonderheiten des Dokumentlayouts und der für das Element InvoiceDateAsString angegebenen Eigenschaften (sein alphabet erlaubt Ziffern) konnte FlexiLayout Studio das Datumsfeld in allen Ketten finden, obwohl tatsächlich nur eine der drei Hypothesen korrekt ist.Da in jeder Group eines der Elemente gefunden wurde, während das andere nicht gefunden wurde, beträgt die endgültige Qualität der Kette in jeder der DateGroup-Groups 0,97 (1 multipliziert mit 0,97, der Standardqualität der Nullhypothese).In diesem Beispiel wirkt sich die endgültige Qualität der DateGroup-Ketten beim Erkennen des Elements InvoiceDateHeader nicht auf das „Gleichgewicht“ zwischen den Hypothesen aus, das heißt, die Qualität jeder Kette wird einfach weiter mit 0,97 multipliziert.Am Ende erzeugte FlexiLayout Studio eine einzige Hypothese für das Gruppenelement InvoiceRequisiteGroup, die der besten Kette in der Group entspricht. Ihre Qualität beträgt ungefähr 0,953, das heißt, der „Gruppenansatz“ half der richtigen Hypothese zum Sieg, obwohl ihre anfängliche Qualität geringer war.
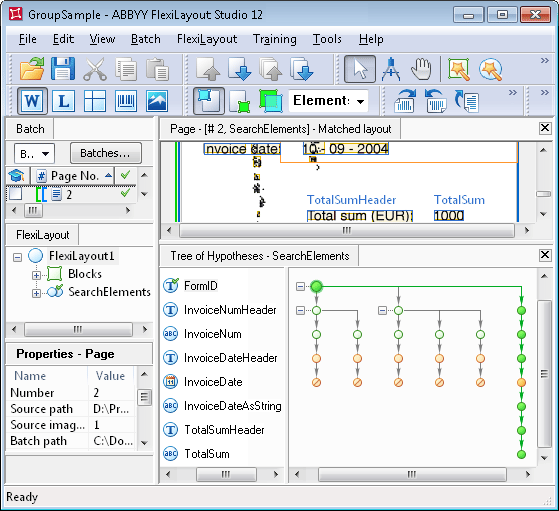
Um zu sehen, wie der Hypothesenbaum ohne Gruppenelemente im FlexiLayout aussehen würde, öffnen Sie das Projekt GroupSample.fsp im Ordner Group\Project2. Der Baum ist in der folgenden Abbildung dargestellt.Wie aus der Abbildung ersichtlich ist, verzweigt sich der Hypothesenbaum nach der Erkennung des Elements FormID, weil für das Element InvoiceNumHeader mehrere Hypothesen erzeugt werden. Daher muss FlexiLayout Studio die Qualität jeder einzelnen Kette vergleichen, wobei es jedes Mal beim allerersten Element beginnt und bis zum letzten nach unten geht.Außerdem erzeugt ein FlexiLayout ohne Gruppenelemente bei jedem Dokument mit einem komplexeren Layout als in diesem Beispiel einen Hypothesenbaum mit zu vielen Verzweigungen, was den Abgleich des FlexiLayouts erschwert.
Vermeiden Sie es, alle gesuchten Elemente in einer einzigen Wurzel-Group zu platzieren. Das eignet sich nur für sehr einfache FlexiLayouts mit weniger als 10 Elementen, was bei realen Aufgaben nur sehr selten vorkommt.Wenn die Anzahl der Elemente in der Wurzel-Group steigt, wächst auch die Anzahl der Hypothesen stark an, bis entweder das Limit von 10.000 erreicht ist oder der für den Hypothesenbaum zugewiesene Speicher vollständig aufgebraucht ist. In beiden Fällen kann der Abgleich des FlexiLayouts fehlschlagen.
Bei realen Aufgaben ist es in der Regel nicht nötig, alle möglichen Kombinationen jeder Hypothese eines Elements mit jeder Hypothese jedes anderen Elements zu untersuchen, da die meisten Elemente unabhängig voneinander erkannt werden können.Deshalb sollten Sie Elemente in möglichst kleine Gruppenelemente gruppieren, um die Anzahl der zu analysierenden Kombinationen zu verringern und die Suche zu beschleunigen.
Ein nicht gruppierter Hypothesenbaum hat zu viele Verzweigungen, und seine visuelle Analyse ist schwierig.
Da die Qualität der endgültigen Kette außerdem durch Multiplikation der Qualitäten aller Hypothesen in dieser Kette berechnet wird, kann der Rechenaufwand in einem Baum mit zu vielen Verzweigungen deutlich höher sein, was den Abgleich des FlexiLayouts verlangsamt.