Der Einfachheit halber wird in diesem Beispiel ein einseitiges Dokument verwendet.
FuzzyQuality sowie die Funktionen der Gruppe Nearest (Nearest, NearestX, NearestY).
Wie sich die Funktionen Nearest und FuzzyQuality unterscheiden
Nearest kann nur im Feld Advanced pre-search relations verwendet werden. Sie legt fest, dass das Programm unter mehreren Hypothesen eines Elements diejenige auswählen muss, die dem in den Eigenschaften der Funktion Nearest angegebenen Element oder Punkt im Bild am nächsten ist.
Im Feld Advanced pre-search relations des Elements kann nur eine Funktion aus der Gruppe Nearest verwendet werden. Nach ihrer Ausführung bleibt nur eine Hypothese übrig; dies geschieht in der Phase der Hypothesengenerierung, also bevor der im Feld Erweiterte Nach-Suchbeziehungen angegebene Code ausgeführt wird.
Der Parameter Minimum quality, der die Mindestqualität von Hypothesen für das Element angibt, kann für die Elemente Static Text, Zeichenkette, Paragraph, Date und Separator angegeben werden.
Es gibt keine Garantie dafür, dass die verbleibende Hypothese die beste ist (und dem gewünschten Objekt im Bild entspricht), da Erweiterte Nach-Suchbeziehungen für die Zuweisung eines Qualitätswerts an eine Hypothese sehr wichtig sind. Bei Verwendung der Funktion Nearest erfolgt die Auswahl der Hypothese in der Phase der Hypothesengenerierung und basiert auf der Nähe zu einem Punkt, nicht auf der Qualität der Hypothese.
Wenn die im Abschnitt Erweiterte Nach-Suchbeziehungen angegebenen Eigenschaften für die korrekte Auswahl der Hypothese wichtig sind, sollte daher statt der Funktionen der Gruppe Nearest die Funktion FuzzyQuality verwendet werden.
Die Funktion FuzzyQuality kann nur im Abschnitt Erweiterte Nach-Suchbeziehungen verwendet werden. Anders als die Funktionen der Gruppe Nearest wählt sie keine einzelne Hypothese aus, sondern beeinflusst die Gesamtqualität aller generierten Hypothesen anhand der Eigenschaften dieser Hypothesen und der Parameter der Funktion FuzzyQuality.
Außerdem kann die Funktion FuzzyQuality für ein einzelnes Element im Feld Erweiterte Nach-Suchbeziehungen mehrfach verwendet werden. Das bedeutet, dass auf eine Hypothese mehrere unterschiedliche Bedingungen mit verschiedenen Qualitätswerten angewendet werden können. Alle Werte werden multipliziert, um die Post-search quality der Hypothese zu bestimmen.
Die Funktion FuzzyQuality sieht wie folgt aus:
Das Beispielprojekt FuzzyAndNearest
Nearest und FuzzyQuality auf den folgenden Bildern verwendet werden können.
 |  |
|---|---|
 |  |
1.fsp (Ordner %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\FuzzyAndNearest \Project1).
Um die FlexiLayout-Struktur zu optimieren und der Logik hinter der Anordnung der gesuchten Felder im Dokument zu folgen, fasst das Projekt alle gesuchten Elemente in einem zusammengesetzten Element, InvoiceGroup, zusammen.
Die Erstellung des FlexiLayouts könnte mit einem Element beginnen, das die Suchbedingungen für die Bezeichnung des Feldes „Rechnungsnummer“ beschreibt. Eine Analyse der Bilder zeigt jedoch, dass das Wort „Invoice“, aus dem die Bezeichnung besteht, im Dokument mehrmals vorkommt.
Da sich die relative Position der Felder jedes Mal ändert, ist es unmöglich, Bedingungen anzugeben, die eine korrekte Erkennung des Wortes „Invoice“ garantieren. Es kann zum Beispiel auch in der Bezeichnung „Invoice date“ vorkommen.
Um solche Verwechslungen zu vermeiden, beginnt die Beschreibung mit der Bezeichnung des Datumsfelds und verwendet dazu ein Static Text-Element namens DateHeader. Das Feld Search text gibt zwei Werte für die Bezeichnung an: Invoicedate:|Invoicedate (Auflistung der Varianten der Bezeichnung, wie sie auf den Bildern vorkommen). Die Groß-/Kleinschreibung der Bezeichnung spielt dabei keine Rolle.
Weitere Informationen dazu, warum Sie beide Varianten angeben müssen, finden Sie unter Mehrere Static-Text-Werte für Feldnamenvarianten festlegen.
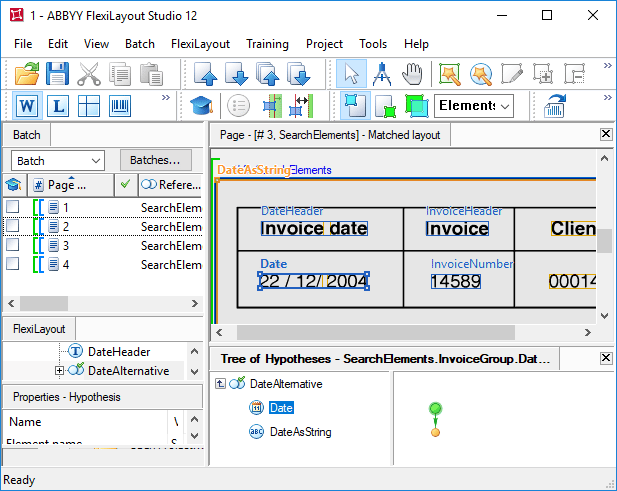
Suche nach dem Datumsfeld mit einem Array von Rechtecken
Eine ausführliche Beschreibung zum Erstellen eines FlexiLayouts für die Datumssuche finden Sie unter Datumssuche nach Erkennung mit hoher oder niedriger Qualität.
Die erste Zeile des Codes (
let Header = InvoiceGroup.DateHeader;) vereinfacht den Code, indem sie die Variable Header definiert und ihr den Wert des Elements DateHeader zuweist.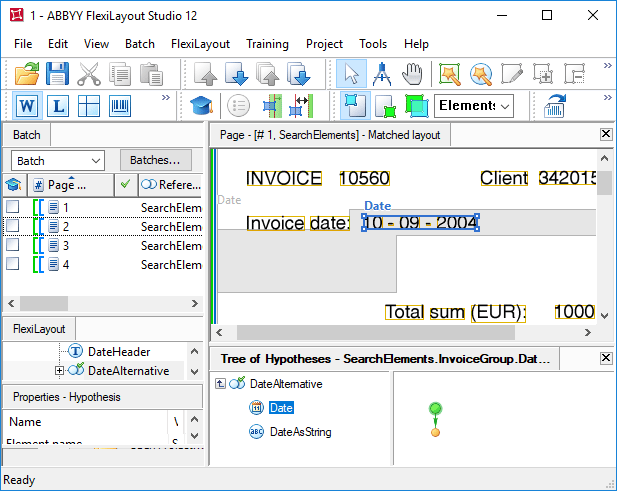
Um den Suchbereich des Elements DateAsString als Array von Rechtecken anzugeben, duplizieren Sie statt
RestrictSearchArea (Date.Rect) den entsprechenden Code aus dem Abschnitt Advanced pre-search relations des Elements Date.Den Namen des Felds „Invoice“ mit Exclude und NearestY erkennen
Weitere Informationen zur optimalen Suche nach Elementen in der Gruppe finden Sie unter Optimize Group element search.
Wenn das FlexiLayout nicht mit dem Namen DateHeader, sondern mit dem Namen InvoiceHeader begonnen hätte, könnte die Funktion
Exclude nicht verwendet werden, da mit dieser Funktion nur Elemente ausgeschlossen werden können, die sich im Projektbaum oberhalb des aktuellen Elements befinden.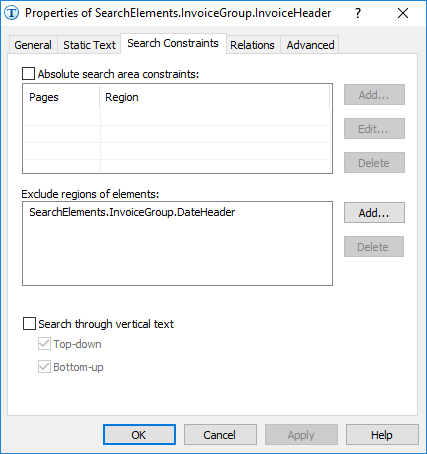
Nearest angegebene Bedingung für beide Strings “Invoice”, weil sie sich auf derselben Höhe befinden. Da die Erkennungsqualität der Strings “Invoice” in beiden Fällen gut ist, erzeugte der Optimierungsalgorithmus nur eine Hypothese statt zwei separater. Leider ist diese Hypothese nicht korrekt.
Suche nach der Rechnungsnummer mit Nearest
Als Alternative (für die Bilder in diesem Projekt) zu
Nearest: Header; könnten Sie NearestY: Header.Rect.YCenter; schreiben, um FlexiLayout Studio mitzuteilen, dass das gesuchte Feld dem Mittelpunkt des Namens vertikal am nächsten ist.Dies könnte das Problem der fehlerhaften Erkennung des Feldes “Rechnungsnummer” auf Seite 4 lösen. Auf Seite 5 hilft es jedoch nicht, weil das gesuchte Feld nach der fehlerhaften Erkennung des Namens “Rechnungsnummer” im Datumsfeld erkannt wird.Nearest durch FuzzyQuality-Strafwerte ersetzen
FuzzyQuality in einer solchen Situation verwendet werden kann.
Dies wird im Projekt 2.fsp demonstriert (Ordner FuzzyAndNearest\\Project2).
Die Einstellungen dieses Projekts sind nahezu identisch mit denen des zuvor beschriebenen Projekts.
Es gibt jedoch einen wesentlichen Unterschied: Die Funktion Nearest wird im Abschnitt Advanced pre-search relations nicht verwendet. Stattdessen enthält der Abschnitt Erweiterte Nach-Suchbeziehungen den folgenden Code:
FuzzyQuality: Rect.Top - PageRect.Top, {0,0,0,50000} * dt; bedeutet, dass, wenn eine Nicht-Null-Hypothese erzeugt wird (die Prüfung if not IsNull wird zuerst ausgeführt), der Abstand zwischen der Position des Elements und dem oberen Rand der Seite bestimmt wird. Das heißt, die Differenz (Rect.Top - PageRect.Top) wird berechnet, und FlexiLayout Studio prüft, ob diese Differenz in das Intervall {0, 0, 0, 50000}*dt fällt.
Eine solche Intervallbeschreibung bedeutet, dass die Qualitätsstrafe direkt vom Abstand zwischen dem Element und dem oberen Rand der Seite abhängt: Je größer der Abstand, desto höher die Strafe.
Wie in Abbildung (a) gezeigt, entspricht bei den angegebenen Parameterwerten die maximale Strafe (1) einem Abstand von 50000dt, während ein Abstand von 1000 Dots (1 Dot entspricht 1/300 Zoll) eine Strafe von 0.02 und ein Abstand von 100dt eine Strafe von 0.002 bedeutet.
Achten Sie bei der Auswahl der Parameter, die die Grenzen des Intervalls festlegen (insbesondere wenn es mehrere Elementprüfungen mit der Funktion
FuzzyQuality gibt), darauf, dass sie die richtige Hypothese nicht so stark bestrafen, dass ihre endgültige Quality niedriger wird als die einer Nullhypothese.Wenn die Quality aller Hypothesen (einschließlich der korrekten) niedriger ist als der Quality-Wert einer Nullhypothese, kann die Nullhypothese ausgewählt werden, das heißt, das Element wird nicht erkannt.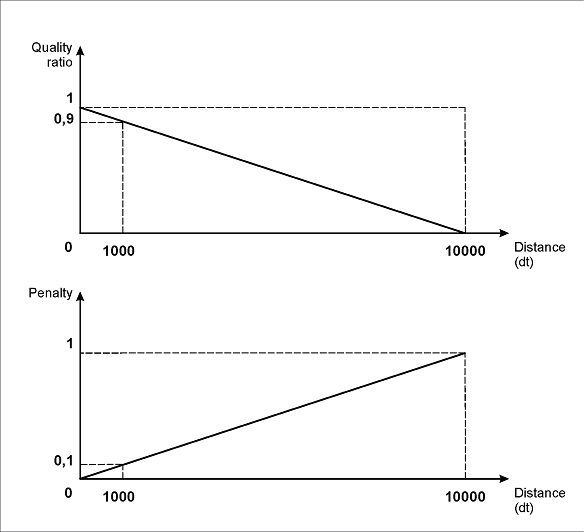
(a)
FuzzyQuality: 500dt - Width, {0,0,0,100000}*dt; bedeutet, dass FlexiLayout Studio die Differenz zwischen 500dt und der Breite des erkannten Objekts berücksichtigt, das der Hypothese entspricht. Das heißt, die Differenz (500dt - Width) wird berechnet, und FlexiLayout Studio prüft, ob diese Differenz in das Intervall {0, 0, 0, 100000}*dt fällt.
Je schmaler das Objekt, desto höher die Strafe, sodass längere Rechnungsnummern bevorzugt werden. Diese Einschränkung kann verwendet werden, wenn das Bild verrauscht ist. Wenn das Rauschen als Zeichen aus dem angegebenen Alphabet erkannt wird (wie beispielsweise auf Seite 2 zu sehen), sollte seine Hypothese bestraft werden, um sie von der weiteren Analyse auszuschließen.
Der Wert 500dt wird anhand einer visuellen Prüfung gewählt, unter der Annahme, dass die String-Länge im Feld “Rechnungsnummer” diesen Wert nicht überschreitet. Die hier angegebenen Parameter legen fest, dass die maximale Strafe (0.005) einer Feldbreite von null für das Feld “Rechnungsnummer” entspricht. Für alle anderen Breiten zwischen 0 und 500dt wären die Qualitätsstrafen geringer.
FuzzyQuality: Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt; bedeutet, dass, wenn eine Nicht-Null-Hypothese für das Element mit dem Namen des Feldes „Rechnungsnummer“ erzeugt wird (zuerst wird die Prüfung if not InvoiceHeader.IsNull ausgeführt), der Abstand zwischen dem Mittelpunkt des erkannten Elements InvoiceNumber und dem Mittelpunkt des Namens InvoiceHeader bestimmt wird. Die Differenz (Rect.XCenter - InvoiceHeader.Rect.XCenter) wird berechnet, und FlexiLayout Studio prüft, ob diese Differenz in das Intervall {-10000, 0, 0, 50000}*dt fällt.
Diese Beschreibung berücksichtigt auch die Möglichkeit, dass sich das Feld „Rechnungsnummer“ unterhalb des Namens befinden kann. In diesem Fall gilt: Je weiter die Elemente voneinander entfernt sind, desto höher ist die Strafe für die entsprechende Hypothese.
Hypothesen, die davon ausgehen, dass sich die Nummer rechts vom Namen befindet, werden nicht so stark bestraft wie diejenigen, die davon ausgehen, dass sich die Nummer unterhalb des Namens befindet, da die „rechte“ Anordnung des Feldes „Rechnungsnummer“ und seines Namens deutlich häufiger vorkommt.
Wie in Abbildung (b) gezeigt, entspricht bei den angegebenen Parametern für die linken und rechten Intervallgrenzen die maximale Strafe (1) einer Verschiebung des Feldes „Rechnungsnummer“ relativ zum Namensfeld um 10000dt nach links oder um 50000dt nach rechts.
Eine Verschiebung um 1000 dots wird mit 0.1 bestraft, wenn es sich um eine Verschiebung nach „links“ handelt, oder mit 0.02, wenn es sich um eine Verschiebung nach „rechts“ handelt. Entsprechend wird eine Verschiebung um 100 dots mit 0.01 bestraft, wenn es sich um eine Verschiebung nach „links“ handelt, oder mit 0.002, wenn es sich um eine Verschiebung nach „rechts“ handelt.
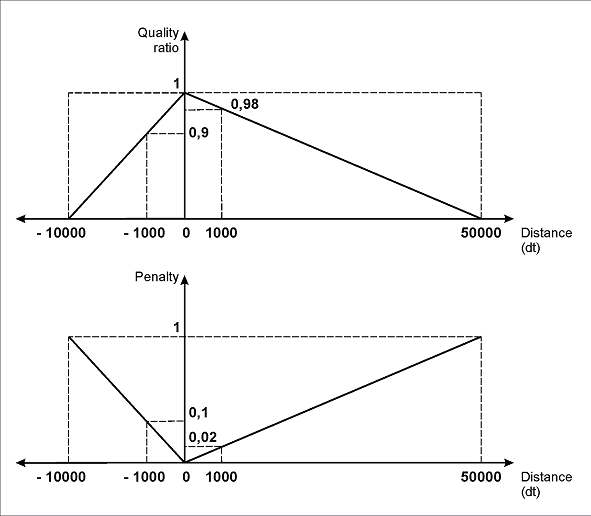
(b)
FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt; ist mit der vorherigen identisch. Sie ist jedoch für Fälle vorgesehen, in denen sich das Feld „Rechnungsnummer“ auf derselben horizontalen Ebene wie das Namensfeld oder sogar leicht darüber befindet. Die Strafen sind hier für jede vertikale Verschiebung gleich.
Die Intervallgrenzen werden nach derselben Logik festgelegt: Hypothesen, die das Datenfeld rechts von seinem Namen finden, sollen priorisiert werden. Das Projekt zeigt jedoch, dass diese Einstellungen die korrekte Erkennung der Rechnungsnummer auch dann nicht verhindert haben, wenn sie sich unterhalb des Namens befand (Seite 3).
Nach dem Abgleich des FlexiLayouts mit allen Seiten können Sie sehen, dass die beiden gesuchten Felder erfolgreich erkannt wurden.
Zusammenfassend ist die Funktion FuzzyQuality effizienter und flexibler als die Funktionen der Gruppe Nearest, was besonders bei der Verarbeitung semi-strukturierter Dokumente wichtig ist.