グループ要素 内の要素チェーンについて、すべての仮説の品質値が 1 の場合、それらの要素のほかの仮説は解析されません。
これは、FlexiLayout を最適化し、マッチング処理を高速化するとともに、仮説ツリーの不要な「分岐」を避けるために行われます。ただし、FlexiLayout Studio にとって最適な仮説が、画像上で探しているオブジェクトに必ずしも対応するとは限りません。これは、要素の検索条件が十分に厳しくない場合に起こり得ます。このような状況が発生した場合は、まず要素検索に設定したパラメーターを解析します。
GO.fsp (フォルダー %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\GO\1) を見てみましょう。
このプロジェクトには 2 つのページがあります。
- ページ 1 – 画質は良好です。
- ページ 2 – 検索対象の field 名にノイズがあります。
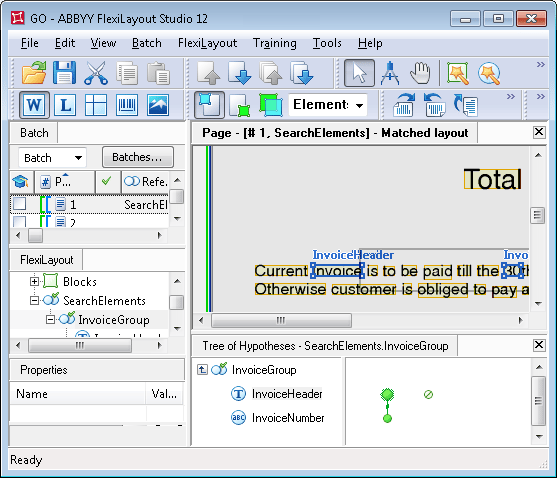
このプロジェクトには InvoiceGroup というグループがあり、その中に field 名を検索するための要素が含まれています。これは、値が「INVOICE」の InvoiceHeader という名前の Static Text 要素です。
field「請求書番号」自体を検索するために、このプロジェクトでは InvoiceNumber という名前の Character String 要素を使用します。名前に対する field の検索条件は、InvoiceNumber 要素の Relations セクションで指定されています。
名前の Search text セクションでは、大文字と小文字は関係ありません。
グループの仮説ツリーを表示するには、仮説ツリー内の グループ要素 の名前をダブルクリックするか、Enter キーを押すか、ショートカットメニューから Show Details を選択します。
Nearest を使って名前をページの右端に関連付ける
Nearest: PageRight;.
これが機能するのは、探している field 名 “請求書番号” が、ページの右端に最も近い唯一の要素だからです。そうでなかったり、文書が定型化されていなかったりする場合は、Nearest function ではこの問題を解決できません。
FuzzyQuality を使用して離れた数字の仮説にペナルティを与える
GO.fsp project (フォルダー GO\2) に示しています。
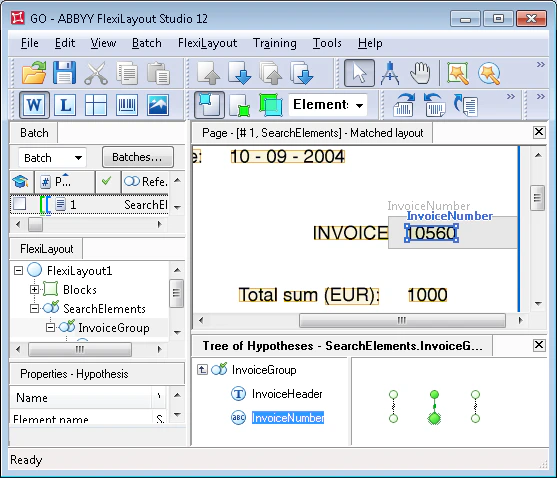
画像を見ると、数字の文字列と単語 “invoice” との距離は、探しているfield “請求書番号” で最も小さいことがわかります。
これはすべてのページに当てはまるため、InvoiceNumber 要素の Advanced post-search relations セクションに次のコードを入力して、生成された仮説の品質値に影響を与えることができます:
これは、両方の要素が検出された場合、要素 InvoiceNumber の仮説について要素間の距離が計算され、その距離が区間 {0, 0, 0, 10000}*dt に含まれるかどうかを FlexiLayout Studio が確認することを意味します。
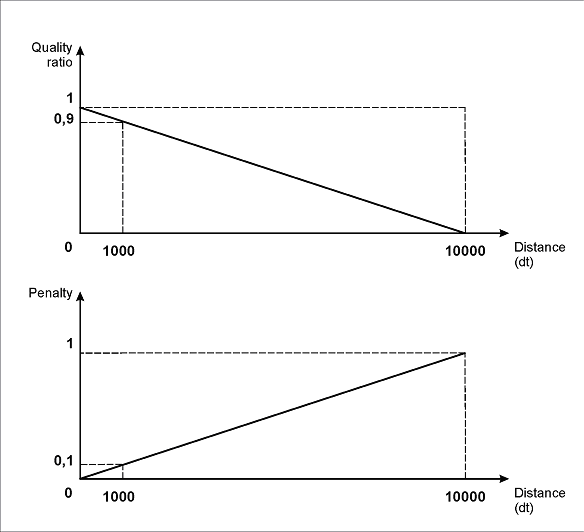
この区間の定義は、仮説のqualityと要素間の距離が線形に依存することを示しています。つまり、距離が長いほどペナルティは大きくなります (関数 FuzzyQuality は仮説のpost-search qualityを返します。これは仮説の Properties ウィンドウで確認できます)。
区間の右境界の値 (10000dt) は、実験によって決定されました。この値を選ぶ際は、テスト画像上の対応するobject間の距離を考慮する必要があります。
次の図に示すように、指定した区間のプロパティでは、最大ペナルティ (1) は距離 10000dt に対応します。したがって、距離が 1000dt の場合のペナルティは 0.1、100dt の場合は 0.01 となり、以下同様です。
したがって、画像で確認できる約 100~300 ドットの実際の距離では、ペナルティ係数は 0.99~0.97 になります。
このbatchの画像では、不要なfield「請求書番号」で値が「2005」の仮説には最大のペナルティが与えられた一方、探しているfieldに対応する仮説には最小のペナルティが与えられました。
ペナルティが加えられたことで、すべての仮説の Post-search quality が 1 ではなくなったため、グループ要素 InvoiceGroup の両方の要素について、すべての仮説が解析されるようになります。
なお、field「請求書番号」は、名前「Invoice」に非常に多くのノイズがあり、その結果認識エラーが発生して仮説に追加のペナルティが課されたページ 2 でも、正しく検出されました。