簡単にするため、このサンプルでは 1 ページの文書を使用します。
FuzzyQuality 関数と、Nearest グループの関数 (Nearest、NearestX、NearestY) が用意されています。
Nearest 関数と FuzzyQuality 関数の違い
Nearest 関数は、Advanced pre-search relations field でのみ使用できます。この関数は、要素の複数の仮説のうち、Nearest 関数のプロパティで設定された画像上の特定の要素または点に最も近いものを FlexiLayout Studio が選択することを指定します。
要素の Advanced pre-search relations field では、Nearest グループの関数は 1 つしか使用できません。これを実行すると、残る仮説は 1 つだけになり、これは仮説生成の段階、つまり Advanced post-search relations field で指定されたコードが実行される前に行われます。
要素の仮説の最小 品質 を指定する Minimum quality parameter は、Static Text、Character String、Paragraph、Date、Separator の各要素に対して指定できます。
ただし、残った仮説が最良であり (画像内の目的のオブジェクトに対応している) とは限りません。というのも、仮説に 品質 値を割り当てるうえで Advanced post-search relations は非常に重要だからです。Nearest 関数を使用する場合、仮説の選択は仮説生成の段階で行われ、その基準は特定の点への近さであり、仮説の 品質 ではありません。
そのため、Advanced post-search relations セクションで指定するプロパティが仮説を正しく選択するうえで重要である場合は、Nearest グループの関数ではなく FuzzyQuality 関数を使用する必要があります。
FuzzyQuality 関数は、Advanced post-search relations セクション でのみ使用できます。Nearest グループの関数とは異なり、単一の仮説を選択するのではなく、生成されたすべての仮説のプロパティと FuzzyQuality 関数の parameters に基づいて、各仮説の overall 品質 に影響を与えます。
さらに、FuzzyQuality 関数は、1 つの要素に対して Advanced post-search relations field 内で複数回使用できます。これは、異なる 品質 値を持つ複数の制約を 1 つの仮説に適用できることを意味します。仮説の Post-search 品質 を決定するために、すべての値が乗算されます。
FuzzyQuality 関数は次のようになります:
FuzzyAndNearest sample Project
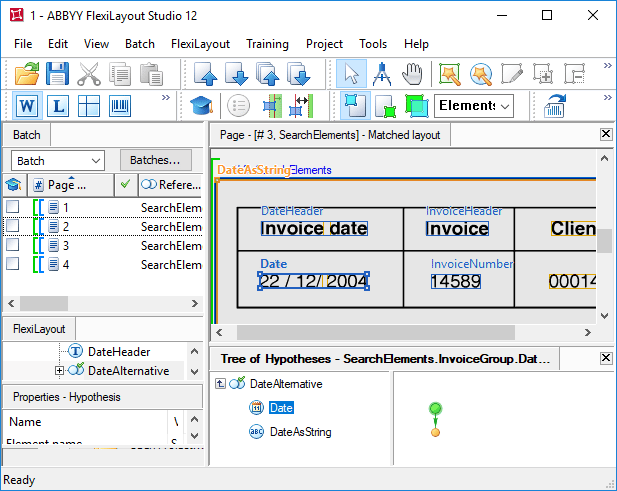
Nearest 関数と FuzzyQuality 関数を次の画像でどのように使用できるかを示します。
 |  |
|---|---|
 |  |
1.fsp Project (フォルダー %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\FuzzyAndNearest \Project1) で行います。
FlexiLayout の構造を最適化し、文書内で対象フィールドがどのように配置されているかというロジックに沿うため、このProjectでは対象となるすべての要素を InvoiceGroup という複合要素にまとめています。
FlexiLayout の作成は、“請求書番号” というフィールド名の検索制約を記述する要素から始めることもできます。しかし、画像を解析すると、その名前を構成する “Invoice” という単語は文書内に複数回現れることがわかります。
各フィールドの相対的な位置は毎回変化するため、“Invoice” という単語を確実に正しく検出できるような条件を指定することはできません。たとえば、この単語は “請求日” という名前の中にも見つかる可能性があります。
このような混同を避けるため、記述は日付フィールド名から始めます。ここでは、DateHeader という名前の Static Text 要素を使用します。Search text フィールドには、名前の 2 つの値 Invoicedate:|Invoicedate を指定します (画像内で実際に現れる表記の候補を列挙しています) 。名前の大文字と小文字の違いは関係ありません。
両方の候補を指定する必要がある理由について詳しくは、field 名の候補に対して複数の Static Text 値を設定する を参照してください。
矩形の配列を使用して日付フィールドを検索する
日付検索用の FlexiLayout の作成方法について詳しくは、認識品質が高い場合または低い場合の日付検索を参照してください。
コードの 1 行目 (
let Header = InvoiceGroup.DateHeader;) では、変数 Header を定義し、要素 DateHeader の値を割り当てることで、コードを簡潔にしています。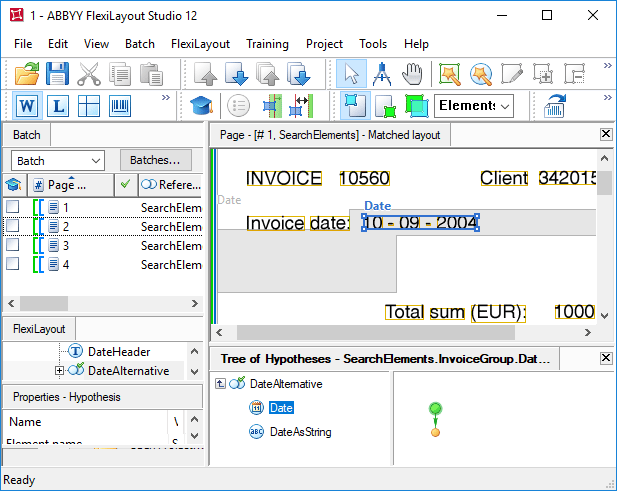
DateAsString 要素の検索領域を矩形の配列として指定するには、
RestrictSearchArea (Date.Rect) を呼び出す代わりに、Date 要素の Advanced pre-search relations セクションにある対応するコードを複製します。Exclude と NearestY を使用して Invoice フィールド名を検出する
グループ内の要素の最適な検索について詳しくは、グループ要素検索の最適化を参照してください。
FlexiLayout が DateHeader ではなく InvoiceHeader から開始されていた場合、
Exclude function は使用できません。この function では、プロジェクトツリー内で現在の要素より上にある要素しか除外できないためです。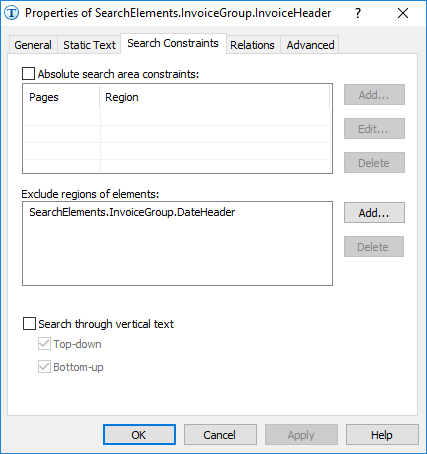
Nearest 関数で指定した制約は、同じ高さに配置されているため、2 つの “Invoice” 文字列の両方に当てはまります。また、どちらの “Invoice” 文字列も認識精度が高いため、最適化アルゴリズムは 2 つの別個の仮説ではなく、1 つの仮説を生成しました。残念ながら、この仮説は正しくありません。
Nearest を使用して請求書番号を検索する
代替案として (現在の Project の画像では) 、
Nearest: Header; の代わりに NearestY: Header.Rect.YCenter; と記述し、目的の field が name の中心に対して垂直方向に最も近いことを FlexiLayout Studio に伝えることもできます。これにより、ページ 4 の “請求書番号” field の誤検出は解消できる可能性があります。ただし、ページ 5 では効果がありません。これは、“請求書番号” という名前が誤って検出された後、目的の field が日付フィールド内で検出されてしまうためです。Nearest を FuzzyQuality ペナルティに置き換える
FuzzyQuality 関数をどのように使用できるかを見ていきます。
これは、2.fsp Project (FuzzyAndNearest\Project2 フォルダー) で示されています。
この Project の設定は、前述の Project の設定とほぼ同じです。
ただし、重要な違いが 1 つあります。Advanced pre-search relations セクションでは Nearest 関数を使用していません。代わりに、Advanced post-search relations セクションには次のコードが含まれています。
FuzzyQuality: Rect.Top - PageRect.Top, {0,0,0,50000} * dt; は、null ではない仮説が生成された場合 (最初に if not IsNull チェックが実行されます) に、要素の位置とページ上端との距離が求められることを意味します。つまり、差分 (Rect.Top - PageRect.Top) が計算され、FlexiLayout Studio はその差分が区間 {0, 0, 0, 50000}*dt に含まれるかどうかを確認します。
このような区間の記述は、品質ペナルティが要素とページ上端との距離に直接依存することを意味します。距離が長いほど、ペナルティは大きくなります。
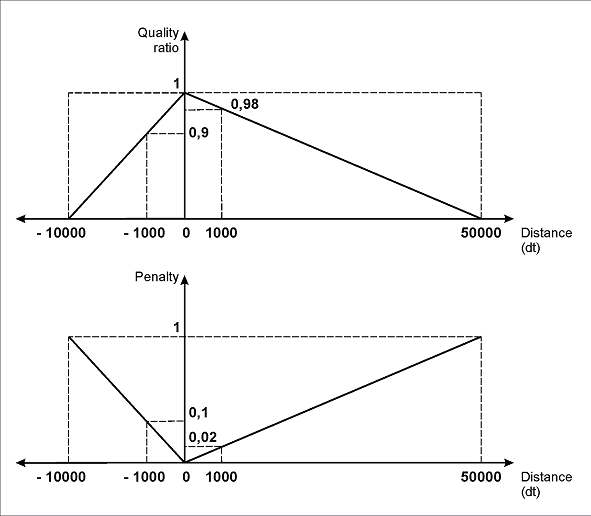
図 (a) に示すように、指定されたパラメーター値では、最大ペナルティ (1) は 50000dt の距離に対応します。一方、1000 ドット (1 ドットは 1/300 インチ) の距離ではペナルティは 0.02、100dt の距離では 0.002 になります。
区間の境界を設定するパラメーターを選択する際は (特に
FuzzyQuality 関数による要素チェックが複数ある場合) 、正しい仮説に過剰なペナルティを与えて、その最終的な品質がヌル仮説の品質より低くならないようにしてください。すべての仮説 (正しいものを含む) の品質がヌル仮説の品質値より低い場合、ヌル仮説が選択されることがあります。つまり、要素は検出されません。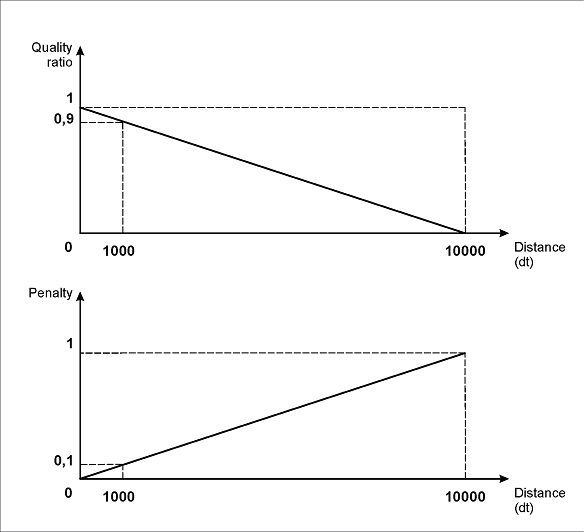
(a)
FuzzyQuality: 500dt - Width, {0,0,0,100000}*dt; は、FlexiLayout Studio が 500dt と、仮説に対応する検出済みオブジェクトの幅との差を考慮することを意味します。つまり、差分 (500dt - Width) が計算され、FlexiLayout Studio はその差分が区間 {0, 0, 0, 100000}*dt に含まれるかどうかを確認します。
オブジェクトの幅が狭いほどペナルティは大きくなるため、より長い請求書番号が優先されます。この制約は、画像にノイズがある場合に使用できます。ノイズが指定されたアルファベットの文字として認識された場合 (たとえばページ 2 で確認できます) 、以降の解析から除外するために、その仮説にペナルティを与える必要があります。
500dt という値は、field “請求書番号” 内の文字列長がこの値を超えないと仮定して、目視で選ばれています。ここで指定されているパラメーターは、field “請求書番号” の幅が 0 の場合に最大ペナルティ (0.005) に対応することを定義しています。0 から 500dt の間のそれ以外の幅では、品質ペナルティはより小さくなります。
FuzzyQuality: Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt; は、「請求書番号」field名の要素に対してヌルでない仮説が生成された場合 (最初に if not InvoiceHeader.IsNull チェックが実行されます) 、検出された InvoiceNumber 要素の中心と InvoiceHeader 名の中心の間の距離を判定することを意味します。差分 (Rect.XCenter - InvoiceHeader.Rect.XCenter) が計算され、FlexiLayout Studio はこの差分が区間 {-10000, 0, 0, 50000}*dt に含まれるかどうかを確認します。
この説明では、field「請求書番号」が名前の下に配置される可能性も考慮しています。この場合、要素同士の距離が離れるほど、対応する仮説に対するペナルティは大きくなります。
番号が名前の右側にあると仮定する仮説は、番号が名前の下にあると仮定する仮説ほど大きなペナルティを受けません。これは、field「請求書番号」とその名前が「右側」に配置されるほうが、はるかに一般的だからです。
図(b)に示すように、区間の左境界と右境界に指定したパラメーターでは、最大ペナルティ (1) は、field「請求書番号」が名前fieldから左に10000dt、または右に50000dtずれた場合に対応します。
1000ドットのずれには、「左」へのずれであれば0.1、「右」へのずれであれば0.02のペナルティが課されます。同様に、100ドットのずれには、「左」へのずれであれば0.01、「右」へのずれであれば0.002のペナルティが課されます。
(b)
FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt; は前のものと同じです。ただし、これは field「請求書番号」が名前のfieldと同じ高さにある場合、またはわずかに上にある場合のために用意されています。ここでのペナルティは、上下方向のずれであればどの場合も同じです。
区間の境界も、データfieldがその名前の右側で見つかる仮説を優先するという同じ考え方に従って設定されています。ただし、このプロジェクトでは、こうした設定を行っても、請求書番号が名前の下に配置されている場合 (3ページ目) でも正しく検出できることが示されています。
すべてのページに対してFlexiLayoutとのマッチングを行うと、探していた2つのfieldが正常に検出されていることがわかります。
結論として、FuzzyQuality 関数は Nearest グループの関数よりも効率的で柔軟性が高く、これは半構造化文書を処理する際に特に重要です。