8 が B、7 が ?、5 が S、4 が H や文字の組み合わせ LI として認識されることがあります。このようなことは、数字同士が「くっついて」いる場合に起こることがあり、タイプライターで記入された文書ではよく見られます。
誤認識文字をアルファベットに追加する
もちろん、考えられる認識候補をすべて指定する必要はありません。画像の品質が悪い場合、そのような候補をすべて見つけ出すのは非常に時間のかかる作業になることがあります。画質が低く、認識結果を予測できない場合は、文字列の長さや文字列内の空白の長さなど、他の要素のプロパティを使用して検索を実行してください。
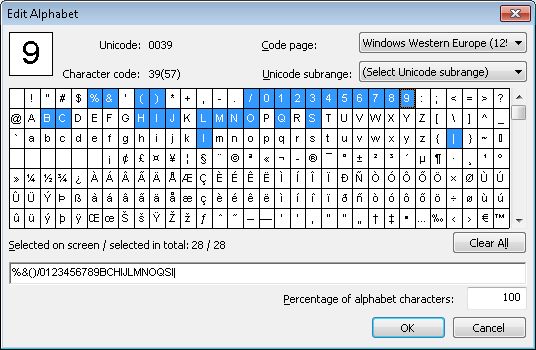
数字のみのアルファベットでマッチングする
1.fsp (フォルダー Digital strings\Project1) を考えます。
このプロジェクトには3つのページがあり、それぞれに異なる認識エラーがあります。
数字列を検出するために、このプロジェクトでは DigitalString という名前の Character String 要素を使用し、そのアルファベットには数字のみを指定しています。数字以外の文字の最大割合は 20% に設定されています。
すべてのページに対して FlexiLayout マッチング手順を実行すると、ページ 3 の数字fieldは完全には検出されませんでした。仮説のQuality値は約 0.98 です。ページ 1 と 2 では文字列は検出されましたが、アルファベットに含まれない文字が含まれているため、対応する仮説にはペナルティが課され、Qualityはそれぞれ 0.978 と 0.982 になっています。
拡張したアルファベットで再マッチングする
L、I、e、a、B、S をアルファベットに追加した場合の FlexiLayout のマッチング結果を見てみましょう。
FlexiLayout のマッチング結果は、プロジェクト 2.fsp (フォルダー %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Digital strings\Project2) で確認できます。
プロジェクト内のその他の設定は同一です。
ご覧のとおり、ページ 3 の文字列は完全に検出され、生成されたすべての仮説の品質は 1 です。