ドキュメント、テーブル、field のさまざまなタイトルや、ドキュメント内のすべてまたは大半の画像に含まれる任意のテキストを検出するために、FlexiLayout Studio では特別な Static Text 要素を使用します。
同じ FlexiLayout で処理する画像ごとに同じ名前の表記ゆれがある場合 (たとえば、field「Invoice number」には「Invoice」、「Invoice:」、「Invoice No.」というバリエーションがある場合) 、句読点だけの違いであっても、考えられる static text の値をすべて指定する必要があります。
すべての static text バリエーションを列挙する必要がある理由
- 指定した値に対応する仮説を生成するためです。たとえば、Invoice: という候補を指定せず、Invoice だけを指定した場合、コロンは field 名の仮説に含まれません。すると、そのコロンが、名前の右側で検索される請求書番号の検索領域に含まれてしまう可能性があります。番号の検索で数字以外の文字や未指定の文字が許可されている場合、そのコロンが請求書番号を表す要素の仮説に入り込むことがあります。
- Search text ウィンドウで指定していない文字によって仮説が減点されるのを防ぐためです。たとえば、Search text セクションで Invoice: を指定していて、処理対象の画像に Invoice# という名前も存在する場合、その要素である程度の誤りが許可されていれば仮説は生成されますが、その品質は減点されます (この例では、FlexiLayout で少なくとも 1 つの誤りが許可されています) 。
- たとえば Invoice|Invoice: のように候補仮説がある場合、FlexiLayout Studio は長い方の仮説にわずかに高い品質を割り当てるため、Invoice: の仮説が優先されます。コロンを含む候補が指定されている場合、Invoice は Invoice: の部分文字列であるため、コロンを含まない方は 0.001 減点されます。もう一方の部分文字列である短い名前文字列を減点することで、長い仮説が winner になります。
StaticText.fsp サンプルプロジェクト
StaticText.fsp (フォルダー %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Variants of StaticText) を使用してみましょう。
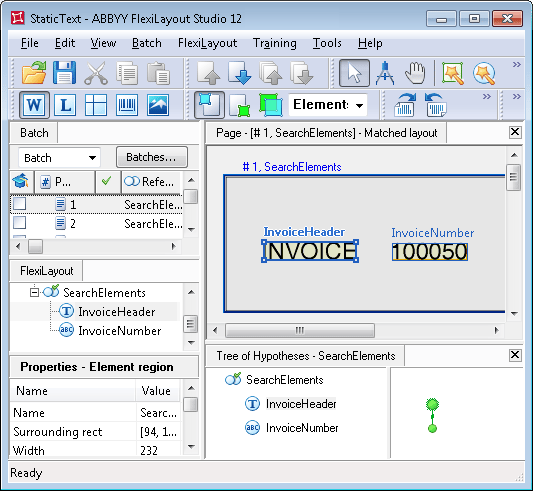
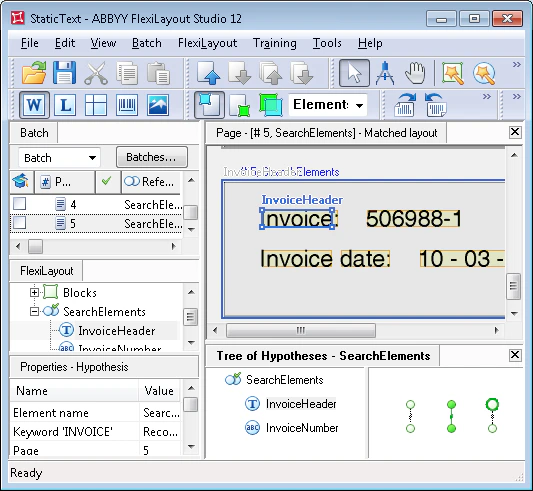
このプロジェクトには 5 ページあり、それぞれのページに Invoice number field 名のバリエーションが示されています。
InvoiceHeader という名前の Static Text 要素の Properties ダイアログでは、処理対象ドキュメント上で見つかる可能性がある field 名をすべて指定しています。この場合は、前述の値です。検索では、名前の大文字と小文字は区別されません: Invoice|Invoice:|Invoice#:|Invoice-。
要素の検索を高速化するため、すべての候補はスペースを入れずに記述しています。スペースの有無は仮説の品質に影響しません。
Invoice 以外のすべての値を削除して再度マッチングする