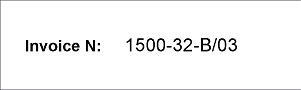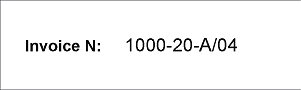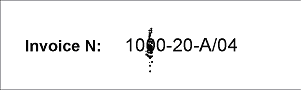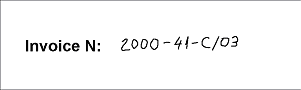単一行fieldを検出するために、FlexiLayout Studio には専用の Character String 要素があります。fieldの形式が既知であれば、要素のプロパティで、Character String タブの Regular expression field にその形式を記述できます。
ただし、正規表現を使用するには、印字文書であり、かつ画質が良好であることが必要です。というのも、正規表現による記述ではfield内の誤りを許容できないため、少しでも誤りがあると要素は検出されないからです。
また、文書のlayoutを記述できる場合でも、手書きで記入された文書に正規表現を使用してはいけません。それでも、そのようなfieldを検出することは可能です。
StructuredStrings.fsp サンプルプロジェクト
StructuredStrings.fsp では、すべてのページで類似した形式を持つ単一行field「請求書番号」を検索する方法を示しています (フォルダー %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Structured strings)。
このプロジェクトには4つのページがあります。
- 1ページ目と2ページ目 – field「請求書番号」は高品質で印字されています。
- 3ページ目 – field「請求書番号」は印字されていますが、画像にノイズがあります。
- 4ページ目 – 画質は良好ですが、field「請求書番号」は手書きで記入されています。
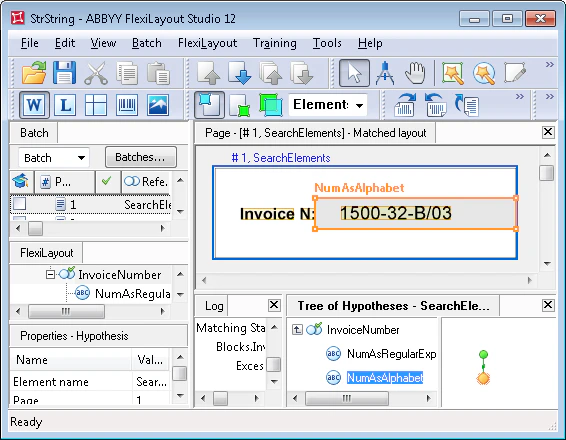
field名を手がかりに 請求書番号 fieldを探します。まず、field名の検索条件を記述する要素が必要です。プロジェクトでは、これは Static Text 要素で、名前は InvoiceNumberHeader、値は InvoiceN: です。
請求書番号 fieldは単一行fieldです。これを検出するために、プロジェクトでは Character String 要素 NumAsRegularExpression を使用します。プロジェクトのページを見ると、請求書番号 fieldの形式は次の正規表現で記述できます。
または (同じ意味ですが)
これは、その番号が「4桁の数字 - 2桁の数字 - 1つのラテン大文字/2桁の数字」という並びであることを意味します。
プロジェクトを見ると、Match コマンドを選択して FlexiLayout のマッチング手順を実行した後、3ページ目と4ページ目では要素 NumAsRegularExpression に対して null 仮説が生成され、つまり要素は検出されませんでした。
3ページ目では、ノイズによってfieldと正規表現の間に不一致が生じました。3ページ目を開いてツールバーの L (Show Recognized Lines) をクリックすると、そのページ上の請求書番号の事前認識結果は 10&0-20-A/04 のように表示されます。
4ページ目では、請求書番号は手書きで記入されています。事前認識結果 (Z.OOO-41-C/03) も、記述された形式に一致していません。
アルファベットを使用したフォールバック用の Character String 要素 を追加する
NumAsAlphabet 要素の検索条件を指定する際は、ドラッグアンドドロップを使用して、NumAsRegularExpression 要素の Relations セクションの設定を現在の要素の同じセクションにコピーできます。あるいは、Advanced pre-search relations field に次のコードを記述することもできます。 SearchElements.InvoiceNumber が指定されています。この段階で、請求書番号 fields を検出するための FlexiLayout は完成です。
何らかの理由で、前述のメソッドだけではデータfield (形式が既知か未知かを問わず) の検出に不十分な場合は、グループ内にもう 1 つ要素 (型は Object Collection) を作成できます。このプロジェクトでは、これは NumAsObjectCollection という名前の Object Collection 要素です。このプロジェクトでは画像の品質が良いため、これは実際には不要で、単なる例として示しているだけです (これには Disable コマンドが指定されています) 。追加の Object Collection 要素が必要になるのは、ページごとの事前認識結果の予測は難しくても、検索領域は正確に記述でき、不要な情報が仮説に入り込むのを防げる場合です。