オブジェクトの検索には、グループ 要素を使用するのが最も効率的です。要素をグループ化すると、各要素に対する仮説の数が減り、その結果、FlexiLayout 全体の仮説の検索が高速になるためです。さらに、要素のグループ化がドキュメントの論理を反映していれば、FlexiLayout の構造の最適化に役立ち、より明確になります。
複数の要素を 1 つのグループ要素にまとめると、FlexiLayout Studio はその要素セット全体を、独自の仮説 (グループ内の各要素の個別の仮説で構成される) を持つ 1 つのまとまりとして扱えるようになります。
仮説とその要素の解析は グループ要素 内で行われ、その後ほかの要素を検索する際には、ユーザーが指定した数の最良の仮説 (既定では 1 個) だけが使用されます。
要素ツリー全体を 1 つのグループ要素と見なすことができ、その最良の仮説が FlexiLayout のマッチング結果になります。
GroupSample.fsp sample プロジェクト
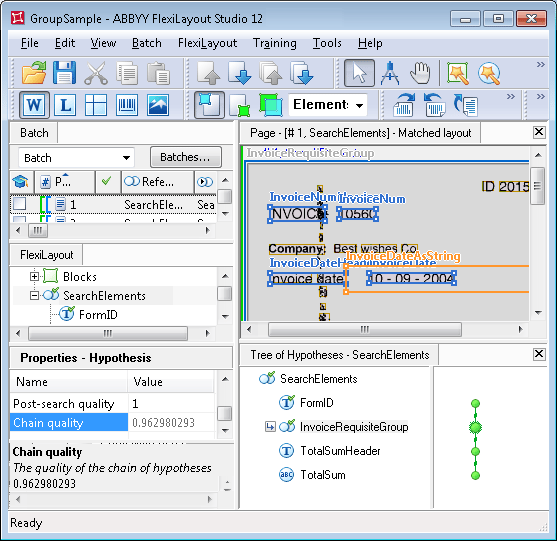
GroupSample.fsp プロジェクト (フォルダー %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Group\Project1) は、グループ要素をどのように使用できるかを示しています。目的は、画像上の請求書番号、請求日、合計金額のフィールドを検出することです。
請求書のフィールドをInvoiceRequisiteGroupにグループ化する
要素をグループ化する前に、特別な識別要素が作成されました。 (識別要素については、ABBYY FlexiCaptureでのFlexiLayoutの識別と処理で詳しく説明されています。) この要素は、その中にグループ要素がある場合とない場合で、仮説ツリーがどのように「分岐」するかを示すためだけに作成されたものです。ツリー内のすべての要素は、識別要素を除いて省略可能であり、それらのヌル仮説のデフォルトの品質は0.97であると仮定します。 要素の設定については、ここでは説明しません。プロジェクト内で直接確認できます。
仮説ツリーは 1 本のチェーンだけで構成されています。グループ の品質は、グループ 内で最良のチェーンの品質と一致します。
Post-search relations はどの要素にも指定されていないため、各要素の Post-search quality は = 1 であり、任意の仮説の品質は Pre-search quality で判断できます。
最良の仮説の検索は グループ 内で行われます。すべてのチェーンの品質が解析され、比較されます。グループ の品質は、グループ 内で最良のチェーンの品質によって決まります。
Dontfind function を使用) 。
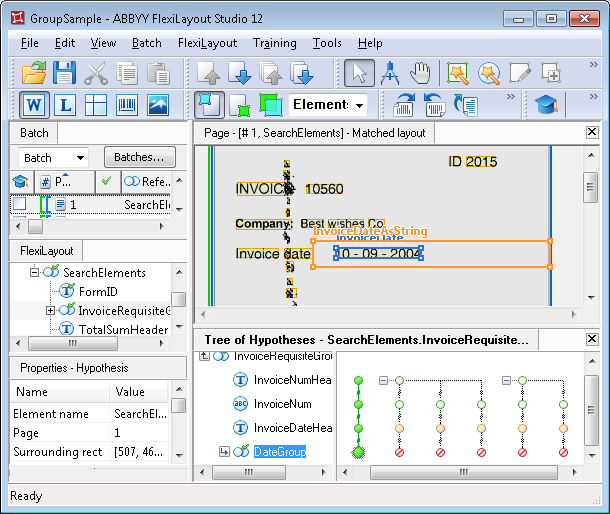
ドキュメントの layout 上の特徴と、InvoiceDateAsString 要素に指定したプロパティ (そのアルファベットは数字を許可する) により、FlexiLayout Studio はすべてのチェーンについて日付フィールドを見つけることができましたが、3 つの仮説のうち実際に正しいのは 1 つだけです。
各 グループ では一方の要素が見つかり、もう一方が見つかっていないため、DateGroup グループそれぞれのチェーンの最終品質は 0.97 です (1 にヌル仮説のデフォルト品質 0.97 を乗算した値) 。
この例では、DateGroup チェーンの最終品質は、InvoiceDateHeader 要素を検出する時点での仮説間の「バランス」に影響しません。つまり、各チェーンの品質にはさらに 0.97 が乗算されます。
最終的に、FlexiLayout Studio はグループ要素 InvoiceRequisiteGroup に対して 1 つの仮説を生成しました。これは グループ 内で最良のチェーンに対応しています。その品質は約 0.953 であり、つまり「グループアプローチ」によって、初期品質が低かったにもかかわらず正しい仮説が勝つことができました。
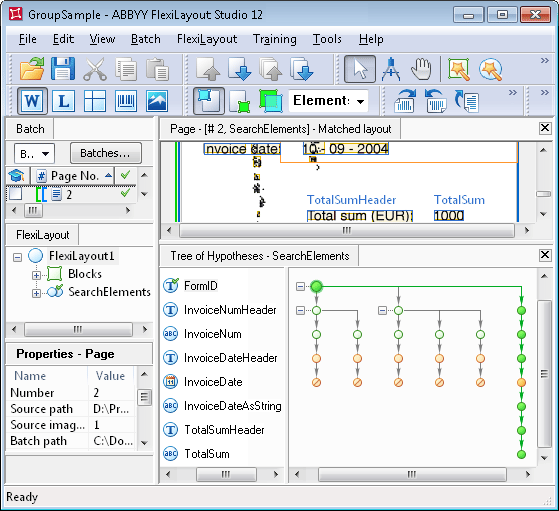
FlexiLayout でグループ要素を使用しない場合に仮説ツリーがどのようになるかを確認するには、Group\Project2 フォルダー内の GroupSample.fsp プロジェクトを開きます。ツリーは次の図に示されています。
図からわかるように、FormID 要素が検出されると、InvoiceNumHeader 要素に対して複数の仮説が生成されるため、仮説ツリーは分岐します。その結果、FlexiLayout Studio は各チェーンの品質を比較するために、その都度、先頭の要素から末尾の要素までたどる必要があります。
さらに、この例より複雑なレイアウトのドキュメントでは、グループ要素のない FlexiLayout は分岐が多すぎる仮説ツリーを生成するため、FlexiLayout のマッチングはいっそう難しくなります。
探している要素をすべて 1 つのルートグループに配置することは避けてください。これは、要素数が 10 未満の非常に単純な FlexiLayout にのみ適していますが、実際のタスクでそのようなケースはごくまれです。ルート グループ 内の要素数が増えると、仮説の数は急激に増加し、10,000 という上限に達するか、仮説ツリーに割り当てられたメモリを使い切るまで増え続けます。どちらの場合でも、FlexiLayout のマッチングに失敗する可能性があります。
グループ化されていない仮説ツリーは分岐が多すぎるため、見た目で解析するのが困難です。