検索するテキストの記述
正規表現を使用した検索テキストの記述
正規表現の構文
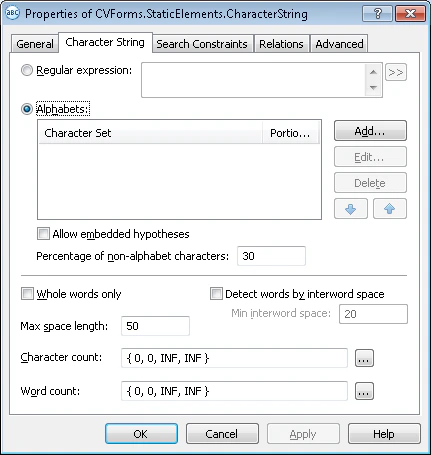
アルファベットを使用して検索テキストを記述する
1
仮説生成モードを選択する
検索領域内の文字を使用して、交差する仮説や埋め込み仮説を含むすべての仮説を生成するには、Allow embedded hypotheses を選択します。最大長の仮説を生成するには、Allow embedded hypotheses をオフにします。
2
1 つ以上のアルファベットを作成する
アルファベットごとに:
- Add… をクリックします。
- Add New Alphabet ダイアログで、Code page リストから必要なコードページを選択します。
- Character map で、検索テキストに含まれる文字を選択します。選択した文字とその数は、Selected on screen/selected in all field に表示されます。
- Percentage of alphabet characters field で、検索テキスト内のアルファベット文字の必要な割合を指定します。
複数のアルファベットを指定できますが、互いに重複してはいけません。つまり、同じ文字を含めることはできません。
Additional Character String properties
- Whole words only – 完全な単語のみを検索します。
-
Detect words by interword space – 行をどのように単語に分割するかを指定します。単語を自動的に検出するには、このオプションを無効にします。有効にすると、隣接する文字間のスペースが Min interword space に入力した値以上になるたびに、行が単語に分割されます。
単語を自動検出する場合、単語の終端はスペース、単語を区切るその他の記号 (たとえば
,、;、/、?) 、またはその他の属性に基づいて検出されます。区切り記号の正確なセットは、選択した事前認識言語によって異なります。FlexiLayout Studio が行を正しく単語に分割できるようにするには、テスト画像上のテキストオブジェクトを確認してください (View → Images → Objects → Recognized Words) 。 -
Word count – ファジー区間を使用して、文字列内の単語数を指定します。デフォルトの区間は
{-1,-1,INF,INF}です (つまり、任意の単語数の仮説が一致します) 。 - Max space length – オブジェクト内のスペースの最大長を、ユーザー定義の単位で指定します。スペースの長さは、隣接するオブジェクトの座標を確認することで見積もることができます。隣接するオブジェクトにマウスカーソルを合わせると、その座標がステータスバーに表示されます。テキストを検索する際は、隣接する要素間の距離が Max space length を超えるまで、文字列に文字が追加されます。
-
Character count – ファジー区間を使用して文字列の長さ (文字数) を指定します。これは、長さに基づいて仮説の品質も評価します。
 ボタンを使用すると、ファジー区間を別ウィンドウで指定し、視覚的に確認できます。
ボタンを使用すると、ファジー区間を別ウィンドウで指定し、視覚的に確認できます。