Static Text は、あらかじめ定義されたテキストを表す FlexiLayout の要素です。テキストは、単語または語句で構成できます。語句は、少なくとも 1 つのスペースを含む点で単語とは異なります。また、語句は複数行で記述できます。
Static Text 要素は、FlexiLayout ツリー内で  で示されます。
プログラムは Static Text 要素を使用して、静的テキスト、つまりあらかじめ分かっているテキストを検索します。プログラムは、事前認識 中に検出され、要素の検索領域内にある 認識済みの単語 および Recognized Lines オブジェクトを、静的テキストの候補として扱います。
通常、バッチ内のすべてまたは多くの画像には静的テキストが含まれています。これは、文書の見出し (たとえば、Invoice) や field 名 (たとえば、Date、To:、From:) である場合があります。
このようなオブジェクトは、事前認識中に 認識済みの単語 として検出され、通常は対応する field に入力できるテキストを探す際の「目印」として使用されます。たとえば、静的テキスト “Date” の隣に日付があると考えるのは自然です。
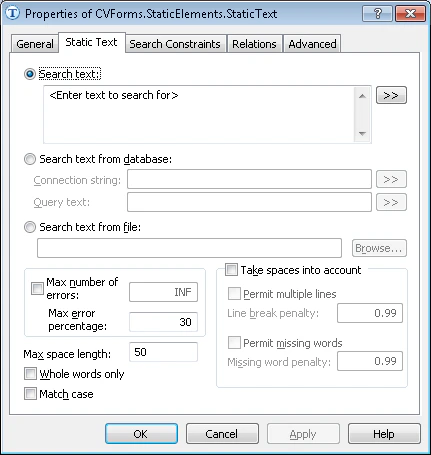
Static Text 要素のプロパティは、要素の プロパティ ダイアログの Static Text タブで設定します。
プロパティ ダイアログを開くには、FlexiLayout ツリーで要素を右クリックし、ショートカットメニューの プロパティ… を選択します。
画像上で検索するテキストです。
フレーズや複数の単語を検索する必要があり、それらが常に同じ行にあることがわかっている場合は、検索を高速化するため、スペースを無視します (スペースを考慮する オプションはオフのままにします) 。
この場合、検索フレーズはスペースを入れずに入力できます。スペースを考慮する オプションが選択されていないと、プログラムがスペースを自動的に削除するためです。たとえば、すべてのドキュメントで 1 行に記載されている ‘Purchase Agreement’ という名前を検索するには、
で示されます。
プログラムは Static Text 要素を使用して、静的テキスト、つまりあらかじめ分かっているテキストを検索します。プログラムは、事前認識 中に検出され、要素の検索領域内にある 認識済みの単語 および Recognized Lines オブジェクトを、静的テキストの候補として扱います。
通常、バッチ内のすべてまたは多くの画像には静的テキストが含まれています。これは、文書の見出し (たとえば、Invoice) や field 名 (たとえば、Date、To:、From:) である場合があります。
このようなオブジェクトは、事前認識中に 認識済みの単語 として検出され、通常は対応する field に入力できるテキストを探す際の「目印」として使用されます。たとえば、静的テキスト “Date” の隣に日付があると考えるのは自然です。
Static Text 要素のプロパティは、要素の プロパティ ダイアログの Static Text タブで設定します。
プロパティ ダイアログを開くには、FlexiLayout ツリーで要素を右クリックし、ショートカットメニューの プロパティ… を選択します。
画像上で検索するテキストです。
フレーズや複数の単語を検索する必要があり、それらが常に同じ行にあることがわかっている場合は、検索を高速化するため、スペースを無視します (スペースを考慮する オプションはオフのままにします) 。
この場合、検索フレーズはスペースを入れずに入力できます。スペースを考慮する オプションが選択されていないと、プログラムがスペースを自動的に削除するためです。たとえば、すべてのドキュメントで 1 行に記載されている ‘Purchase Agreement’ という名前を検索するには、PURCHASEAGREEMENT と入力します。
候補を区切るには、縦線 (| 記号) を使用します。たとえば、類似するドキュメントの名前が Contract または Agreement の場合は、CONTRACT|AGREEMENT と入力します。
フレーズの候補は中かっこで囲み、縦線で区切ります。形式は { }|{ } です。フレーズ内の単語の候補を列挙することもできます (この場合、スペースを考慮する オプションを選択する必要があります) 。
たとえば、検索テキスト フィールドに {SALE|PURCHASE AGREEMENT|CONTRACT}|{CUSTOMER|CLIENT APPLICATION} と入力すると、プログラムは次のフレーズを検索します: sale agreement、purchase agreement、sale contract、purchase contract、customer application、client application。
長い文字列を入力するには、 をクリックして、別のデータ入力ウィンドウを開きます。
データベース内のテキストフラグメントを画像内で検索します。
をクリックして、別のデータ入力ウィンドウを開きます。
データベース内のテキストフラグメントを画像内で検索します。SELECT コマンドで始まる SQL クエリで、テーブル内の該当する field を検索します。次に、プログラムは見つかった field に含まれるテキストを画像内で検索します。
接続文字列を設定する
接続文字列 field にデータベース接続文字列を入力するか、 をクリックして標準のデータベース接続ダイアログを開きます。 クエリを入力する
クエリテキスト field にクエリを入力します。 をクリックして、別のデータ入力ウィンドウを開くこともできます。 Static Text 要素を作成する際の推奨事項
-
選択した静的テキストがすべての画像で確実に認識されることを確認するには、
 または
または  をクリックして、それぞれ単語または語句について事前認識結果を確認します。文字が正しく単語にまとまり、単語が正しく行にまとまっていることを確認してください。
をクリックして、それぞれ単語または語句について事前認識結果を確認します。文字が正しく単語にまとまり、単語が正しく行にまとまっていることを確認してください。
-
大きめの文字で印字され、低品質のスキャンでも同じように認識される静的テキストや、OCR誤認識の数を予測しやすい静的テキストを選ぶのが最適です。
-
文書に、小さい文字で印字された静的テキストしか含まれておらず、事前認識で確実に認識できない場合 (つまり、画像間で誤りの数や種類が大きく異なる場合) は、そのようなテキスト フラグメントは Static Text ではなく、Text および Punctuation mark オプションを選択した Object Collection として定義してください。
Picture オプションも選択する必要がある場合があります。ツールバーの
 (生オブジェクト) をクリックし、画像上で対応するオブジェクトを選択します。オブジェクトの型は、プロパティ ウィンドウの DataType 行に表示されます。
(生オブジェクト) をクリックし、画像上で対応するオブジェクトを選択します。オブジェクトの型は、プロパティ ウィンドウの DataType 行に表示されます。
-
誤検出を防ぎ、追加の検索条件を最小限に抑えるため、固有の静的テキスト フラグメントを選択することが望まれます。
-
1 語だけの名前 (Static Text 要素で見つける予定のもの) と、その 1 語だけの名前と同じ単語を含む語句名の両方がある場合は、まず語句の要素を作成してください。これにより、プログラムが語句名の中から 1 語だけの名前を誤って検出するのを防げます。
中国語、日本語、韓国語の文字列では、検索Parameterを使用できます。このParameterは、見つかった認識候補に含まれるエラー数を、検索テキスト 要素で指定した値と比較する際の数え方に影響します。
このParameterを有効にすると、置換文字として形の似た文字だけが許可されます。挿入、削除、replacementの各operationは、それぞれ1つのエラーとして数えられます。
そのため、ある文字を似た文字に置き換える場合はエラー1件として数えられますが、似ていない文字に置き換える場合は、文字の削除と新しい文字の挿入という2つのoperationが行われるため、エラー2件として数えられます。
この検索モードは、中国語、日本語、韓国語の文字列にのみ影響します。
これらのlanguageでは、テキストが明確に単語へ区切られていないことが多いため、単語単位での完全一致検索は使用できません。
SuggestOnlySimilarChars パラメーターは false に設定されています。